I have the following pandas dataframe:
import numpy as np
import pandas as pd
import plotly.express as px
df1 = pd.DataFrame({'Name_City': ['Paris', 'Rio', 'Madri',
'Lisboa', 'Santiago', 'Toronto',
'Porto', 'Rio', 'Paris',
'Paris', 'Paris', 'Rio',
'Lisboa', 'Lisboa', 'Lisboa',
'Lisboa', 'Rio', 'Madri'],
'First': ['P', 'R', 'M', 'L', 'S', 'T', 'P', 'R', 'P',
'P', 'P', 'R', 'L', 'L', 'L', 'L', 'R', 'M']})
print(df1)
Name_City First
Paris P
Rio R
Madri M
Lisboa L
Santiago S
Toronto T
Porto P
Rio R
Paris P
Paris P
Paris P
Rio R
Lisboa L
Lisboa L
Lisboa L
Lisboa L
Rio R
Madri M
First I would like to count how many times each city appeared in the dataframe, so I did:
series = df1['Name_City'].value_counts()
df_result = pd.DataFrame(series)
df_result = df_result.reset_index()
df_result.columns = ['City', 'Total']
print(df_result)
City Total
Lisboa 5
Rio 4
Paris 4
Madri 2
Santiago 1
Toronto 1
Porto 1
Note: This first part is working as expected.
In the second part, I would like to build a graph (of the pie type) to represent the five cities that appeared the most. The other cities that appeared less I would like to appear on the chart as "other".
I tried to do the following:
df_result_part = df_result.head(5)
print(df_result_part)
City Total
Lisboa 5
Rio 4
Paris 4
Madri 2
Santiago 1
fig = px.pie(df_result_part,
values='Total',
names='City')
fig.show()
I would need to group the ones that appeared the least and name them "others". I would like to ask how can I do this automatically?
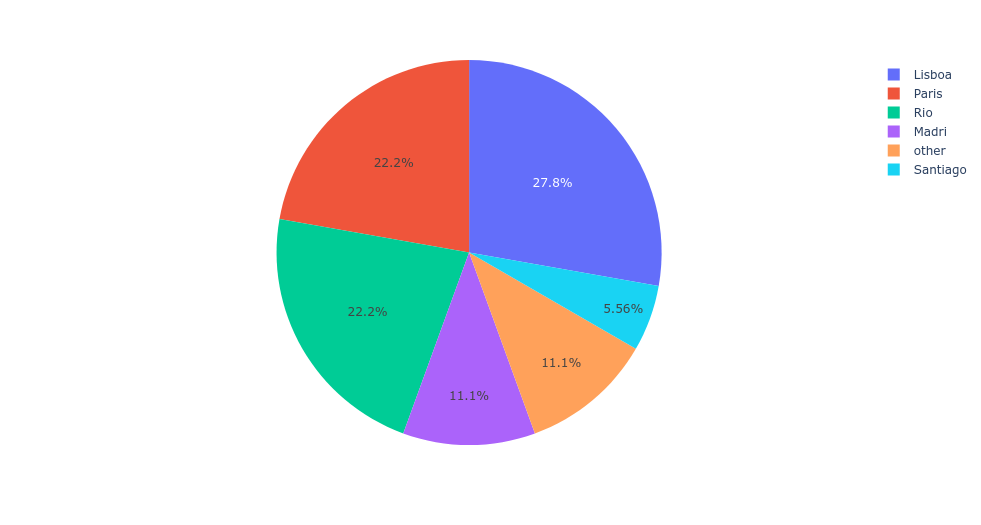
The desired output is:
print(df_desired)
City Total
Lisboa 5
Rio 4
Paris 4
Madri 2
Santiago 1
Others 2
fig = px.pie(df_desired,
values='Total',
names='City')
fig.show()
CodePudding user response:
Starting from df_result, you can select the rows after the fifth one and replace all city names with "other". This will always work as by default value_counts returns its output is sorted order (decreasing counts):
df_result.loc[5:, 'City'] = 'other'
import plotly.express as px
fig = px.pie(df_result,
values='Total',
names='City')
output: