if I have a table for example:
mydataset.itempf containing:
id | item
1 | ABCDEFGHIJKL
2 | ZXDFKDLFKFGF
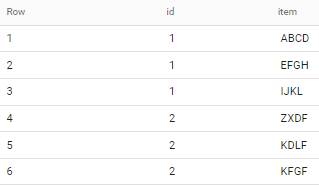
And I would like the "item" field to be split by 4 characters into different rows like:
id | item
1 | ABCD
1 | EFGH
1 | IJKL
2 | ZXDF
2 | KDLF
2 | KFGF
How can I write this in bigquery? Please help.
CodePudding user response:
Use the Substring with the Count Method, That Should make it easier to see which ones are longer than others.
CodePudding user response:
Consider below approach
select id, item
from your_table,
unnest(regexp_extract_all(item, r'.{1,4}')) item
if applied to sample data in your question - output is