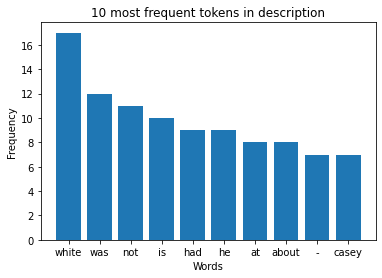
I am using matplotlib, pandas and gensim. I am trying to create a histogram based on frequent words by extracting text directly from a website. I am receiving a typeError in this instance:
text = ','.join(map(str, description_list))
word_frequency = Counter(" ".join(description_list[0]).split()).most_common(10)
from this part of my code:
#start of problems
data = {
"description": [text_corpus]
}
df = pd.DataFrame(data)
description_list = df['description'].values.tolist()
text = ','.join(map(str, description_list))
word_frequency = Counter(" ".join(description_list[0]).split()).most_common(10)
# `most_common` returns a list of (word, count) tuples
words = [word for word, _ in word_frequency]
counts = [counts for _, counts in word_frequency]
plt.bar(words, counts)
plt.title("10 most frequent tokens in description")
plt.ylabel("Frequency")
plt.xlabel("Words")
plt.show()
print(text)
Here is the initial part of my code, which works in extracting textual data from a website:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pprint
from re import X
import string
from tokenize import Token
from collections import Counter
import matplotlib.pyplot as plt
import pandas as pd
url = "https://www.bbc.com/news/world-us-canada-61294585"
html = urlopen(url).read()
soup = BeautifulSoup(html, features="html.parser")
# kill all script and style elements
for script in soup(["script", "style"]):
script.extract()
# get text
text = soup.get_text()
document = text
text_corpus = [text]
# Create a set of frequent words
stoplist = set('for a of the and to in'.split(' '))
# Lowercase each document, split it by white space and filter out stopwords
texts = [[word for word in document.lower().split() if word not in stoplist]
for document in text_corpus]
# Count word frequencies
from collections import defaultdict
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] = 1
# Only keep words that appear more than once
text_corpus = [[token for token in text if frequency[token] > 1] for text in texts]
pprint.pprint(text_corpus)
I am new to Python so please any advice will help. Please let me know If I have something fundamentally wrong with my code, and If i have to restart.
Or if not, if i could be pointed in the right direction in creating graphs from frequent words would be much appreciated or how to convert this particular list into a string.
Additional question: Would it be better to search for specific words from a website instead of extracting all text?
Thank you very much.
CodePudding user response:
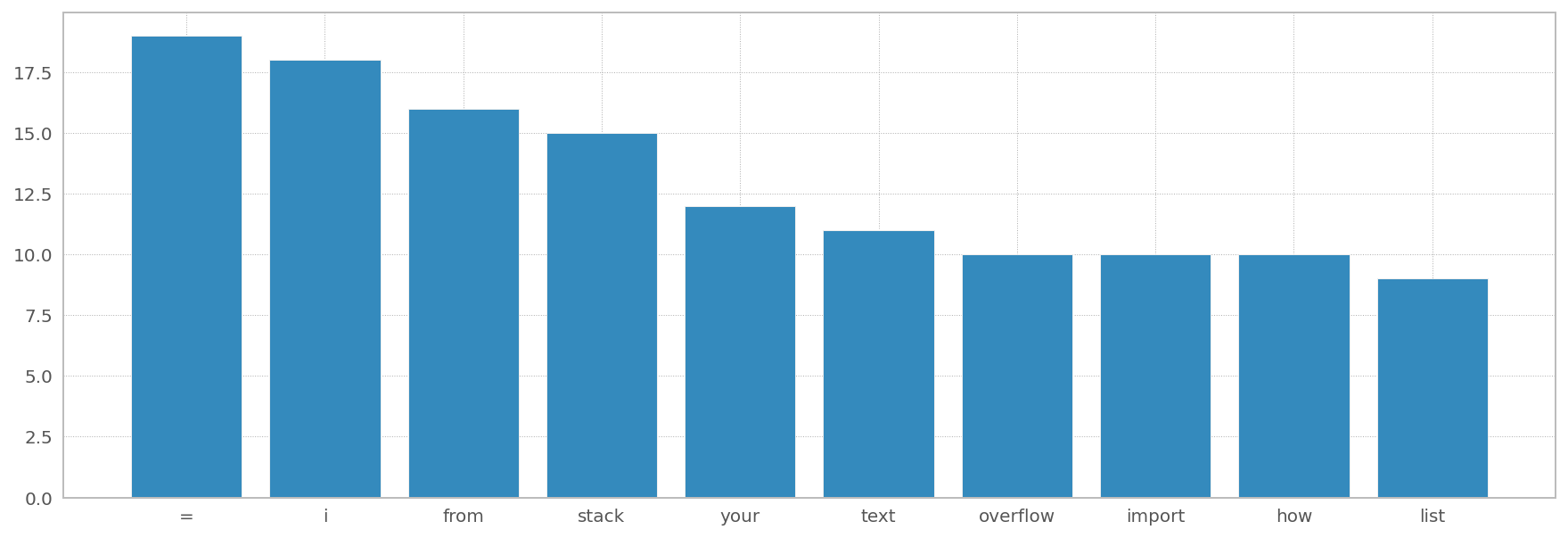
As soon as you've got text_corpus you may proceed as follows:
#url = "https://stackoverflow.com/questions/72091588/can-i-create-a-histogram-bar-graph-from-a-list-in-python-typeerror-expected-st"
counter = Counter(text_corpus[0]).most_common(10)
words, counts = list(zip(*counter))
plt.bar(words, counts)
CodePudding user response:
You missed a [0], it should be:
word_frequency = Counter(" ".join(description_list[0][0]).split()).most_common(10)
Output: