Say I have the following dataframe:
import pandas as pd
df = pd.DataFrame(['4/20/2022 8:23', '4/20/2022 8:20', '4/20/2022 8:20', '4/20/2022 8:20', '4/20/2022 8:20', '4/20/2022 8:20', '4/20/2022 8:17', '4/20/2022 8:17', '4/20/2022 8:17', '4/20/2022 8:17', '4/20/2022 9:56', '4/20/2022 9:50', '4/20/2022 9:50', '4/20/2022 9:48', '4/20/2022 9:48', '4/20/2022 9:48', '4/20/2022 9:48', '4/20/2022 9:47'],
columns=['timestamp'])
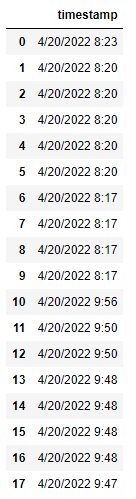
I want to add another column called Cluster which will put all the rows in the same cluster ID if they occur within, say, a half hour time duration. So, rows 0 to 9 should be cluster 0, and rows 10 to 17 should be cluster 1.
How do I do this in the best way?
I'm doing it in quite a patchy way (but at least correctly, I hope):
import numpy as np
df.timestamp = pd.to_datetime(df.timestamp)
df['time_diff'] = np.zeros(len(df))
for i in range(len(df)-1):
df.time_diff[i 1]=np.abs(df.timestamp[i 1]-df.timestamp[i])/ np.timedelta64(1, 'h')
cluster = 0
df['cluster'] = np.zeros(len(df))
for i in range(len(df)):
if df.time_diff[i]>0.5:
cluster =1
df.cluster[i:]=cluster
df
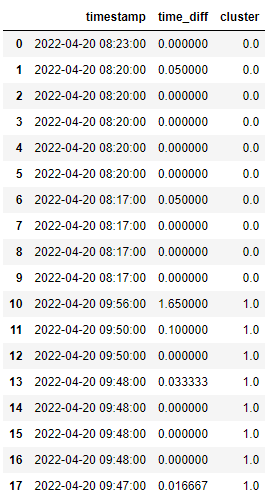
I wonder if there's a Pythonic way of doing this, a one-liner perhaps.
CodePudding user response:
there is a feature precisely for the temporal sequence conversion.
her name is resample.
Below is an example of usage:
import numpy as np
import pandas as pd
start, end = '2000-10-01 23:30:00', '2000-10-02 00:30:00'
rng = pd.date_range(start, end, freq='7min')
df = pd.Series(np.arange(len(rng)), index=rng)
print("before conversion:")
print(df)
print("after conversion:")
print(df.resample('H').sum())
documentation: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.resample.html
CodePudding user response:
You may extract the hour column as follows:
df['timestamp'] = pd.to_datetime(df['timestamp'])
df['hour'] = df['time_stamp'].apply(lambda row: row.hour)