I want to find a way that if the parent include certain child with p, then it extract data from that specific div.
This is what I did but it will still give me the data of other <div> where it doesn't include the <p> as well.
import requests
from bs4 import BeautifulSoup
import smtplib
import os
from csv import writer
for n in range (1, 2):
url = f'https://www.musinsa.com/app/reviews/lists?type=&year_date=2022&month_date=&day_date=&max_rt=2022&min_rt=2009&brand=&page={n}'
headers = {"User-Agent": ""}
page = requests.get(url, headers=headers)
Soup1 = BeautifulSoup(page.content, "html.parser")
Soup2 = BeautifulSoup(Soup1.prettify(), "html.parser")
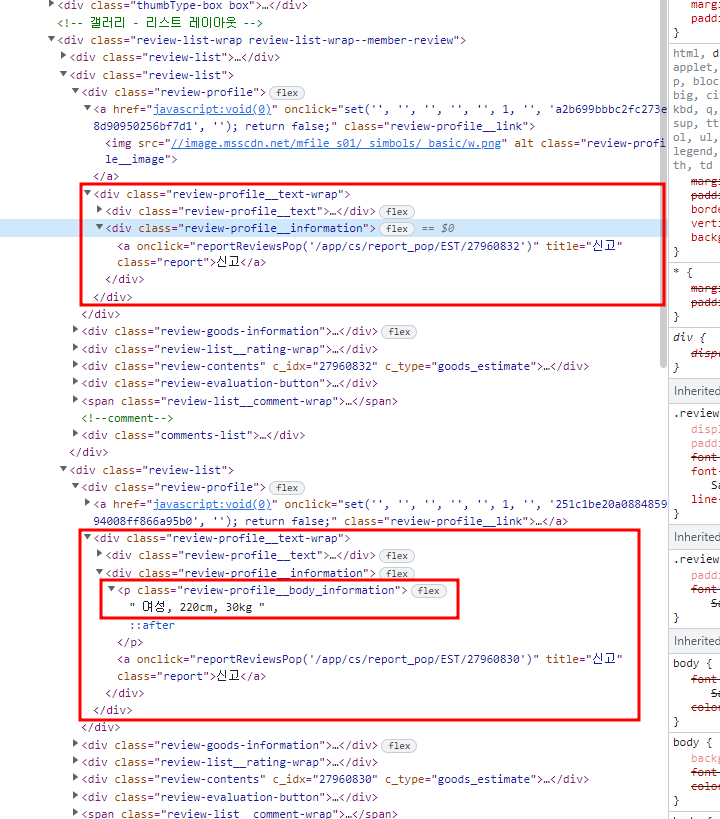
if Soup2.find_all('p', {'class':'review-profile__body_information'}):
ss = Soup2.find_all('p', {'class':'review-profile__body_information'})
product_name = Soup2.find_all('a',{'class':'review-goods-information__name'})
rating = Soup2.find_all('span',{'class':'review-list__rating__active'})
comment = Soup2.find_all('div',{'class','review-contents__text '})
eval = Soup2.find_all('li',{'class':'review-evaluation__item'})
images = Soup2.find_all('li',{'class':'review-content-photo__item'})
allinfo = [ss, product_name, rating, comment, eval, images]
print(allinfo)
How do I need to write so that it will only give me data of 'div' that includes specific <p>? thanks
CodePudding user response:
I recommend you to use XPath. more details about it here: https://www.zyte.com/blog/an-introduction-to-xpath-with-examples/
so what about code? I recommend you to use the lxml module (https://pypi.org/project/lxml/) which supports using xpathes
# pip install lxml
from lxml import html
import requests
url = "your url you want to get"
request = requests.get(url)
# there we convert request content(page) to html class object
page_tree = html.fromstring(request.content)
# to use xpath you need to use this
element = page_tree.xpath("xpath to object")
#to get text of an element
text = element.text
#to get specific value use this
value = element.get("href") #or enother property of an element
So how to get a child? To get a child of an element you need to add "/child::" to the end of your parent XPath for example:
<div class='main_div'>
<div class='parent'>
<p class='content'>
"text you need"
</p>
</div>
</div>
to get "text you need" you can use following xpath: //div[@class='content']/child::p
You need to learn more abouth xpath, it is more simple that using beautiful soup to find elements
CodePudding user response:
One approach could be to select your elements mor specific e.g. with css selectors:
soup.select('div.review-list:has(p.review-profile__body_information)')
You should also change your strategy from generating a lot of lists, better would be to itereate each item, check and pick the needed info.
Example
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0'}
data = []
for n in range (1,3):
url = f'https://www.musinsa.com/app/reviews/lists?type=&year_date=2022&month_date=&day_date=&max_rt=2022&min_rt=2009&brand=&page={n}'
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text)
for e in soup.select('div.review-list:has(p.review-profile__body_information)'):
data.append({
'product_name':e.select_one('.review-goods-information__name').text.strip(),
'comment':e.select_one('.review-contents__text').text.strip(),
'something':'more ...'
})
data
Output
[{'product_name': '[패키지] DUMBY BEAR 2PACK T-SHIRTS',
'comment': '중학생 둘째아들 입힐려고 구매했습니다 \n편하고 이쁘네요. 잘 입을거 같아요',
'something': 'more ...'},
{'product_name': '컴피 워셔 후드 숏 자켓_차콜',
'comment': '주문한지 얼마 되지 않아서 바로 도착을 하였네요',
'something': 'more ...'},
{'product_name': '컬러플러스 미니로고 버뮤다 숏팬츠 MINT GREEN',
'comment': '색상도 이뿌고 반바지 기장도 넉넉하니 부담없이\n자주 입게 되겠네요~',
'something': 'more ...'},
{'product_name': 'CARGO STRING PANTS _ OLIVE',
'comment': '검은색 사고 재구매인데 너무 편하고 이쁩니다 \n만족!',
'something': 'more ...'}]