This question is a spin-off of the one posted here: 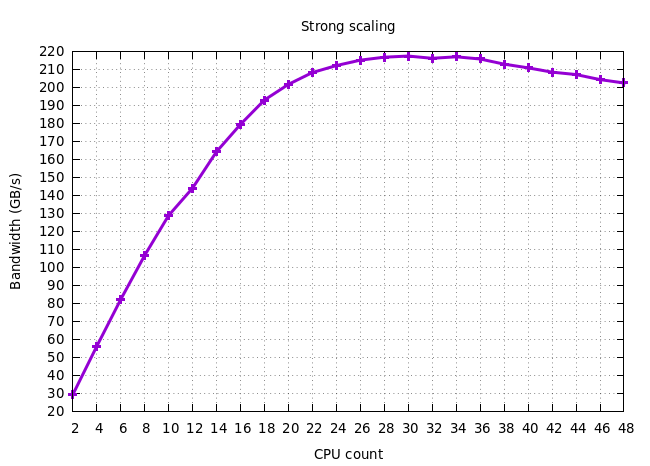
Question: If you look at the strong scaling diagram, you can see that the peak effective bandwidth is actually achieved at 33 CPUs, following which adding CPUs only reduces it. Why is this happening?
CodePudding user response:
Overview
This answer provides probable explanations. Put it shortly, all parallel workload does not infinitely scale. When many cores compete for the same shared resource (eg. DRAM), using too many cores is often detrimental because there is a point where there are enough cores to saturate a given shared resource and using more core only increase the overheads.
More specifically, in your case, the L3 cache and the IMCs are likely the problem. Enabling Sub-NUMA Clustering and non-temporal loads should improve a bit the performances and the scalability of your benchmark. Still, there are other architectural hardware limitations that can cause the benchmark not to scale well. The next section describes how Intel Skylake SP processors deal with memory accesses and how to find the bottlenecks.
Under the hood
The layout of Intel Xeon Skylake SP processors is like the following in your case:
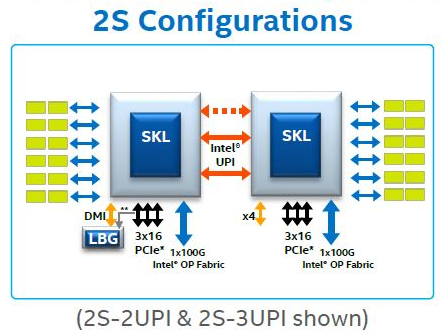
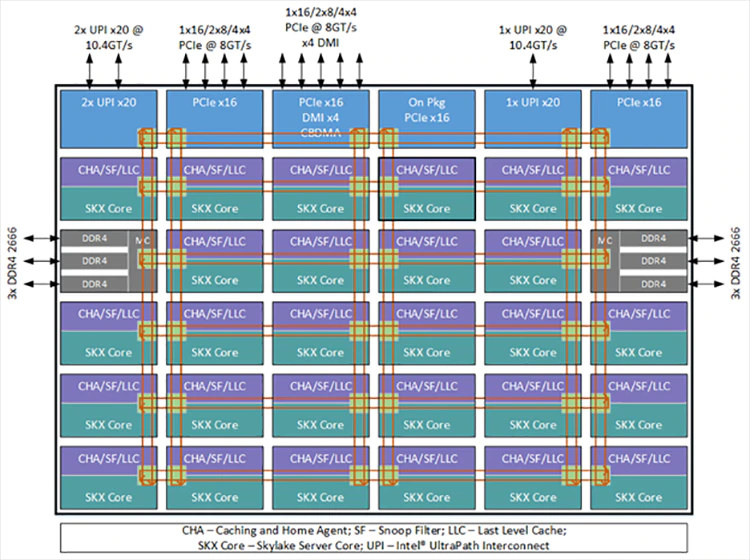
Source: 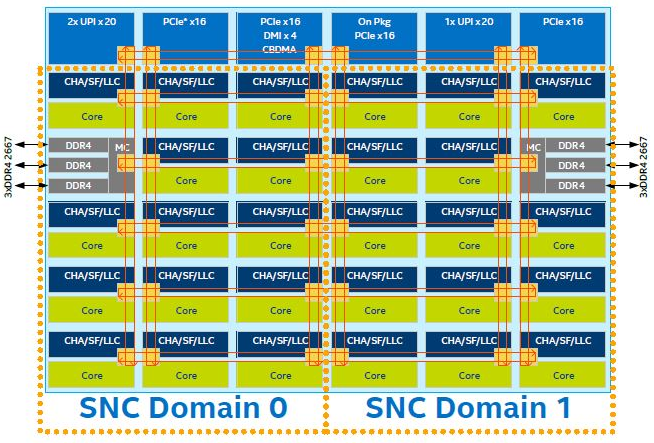
Source: Intel
Furthermore, having more cores accessing the L3 in parallel can cause more early evictions of prefetched cache lines which need to be fetched again later when the core actual need them (with an additional DRAM latency time to pay). This effect is not as unusual as it seems. Indeed, due to the high latency of DDR4 DRAMs, hardware prefetching units have to prefetch data a long time in advance so to reduce the impact of the latency. They also need to perform a lot of requests concurrently. This is generally not a problem with sequential accesses, but more cores causes accesses to look more random from the caches and IMCs point-of-view. The thing is DRAM are designed so that contiguous accesses are faster than random one (multiple contiguous cache lines should be loaded consecutively to fully saturate the bandwidth). You can analyse the value of the LLC-load-misses hardware counter to check if more data are re-fetched with more threads (I see such effect on my Skylake-based PC with only 6-cores but it is not strong enough to cause any visible impact on the final throughput). To mitigate this problem, you can use non-temporal loads so to request the processor to load data directly into the line fill buffer instead of the L3 cache resulting in a lower pollution (here is a related answer). This may be slower with fewer cores due to a lower concurrency, but it should be a bit faster with a lot of cores. Note that this does not solve the problem of having fetched address that looks more random from the IMCs point-of-view and there is not much to do about that.
The low-level architecture DRAM and caches is very complex in practice. More information about memory can be found in the following links: