Experts here, I am searching for your help if you don't mind it.
Recently, I am working out a web crawler using scrapy and selenium in python. My mind has crush.
I just want to ask whether it is possible that you still get empty even if you've used the statement
WebDriverWait(driver, 100, 0.1).until(EC.presence_of_all_elements_located((By.XPATH,xxxxx)))
to get those elements. And also, it even doesn't take 100 second to get empty. Why?
And by the way, it is a random thing, which means this phenomenon happens anywhere, anytime.
Does getting empty had something about my network connection?
Could you help me or give me some opinions, suggestion about the question above?
Thanks a lot!
-----------------------supplementary notes-----------------------
Thanks for the heads up.
In summary, I used scrapy and selenium to crawl a site about reviews and write the username, posting time, comment content, etc. to a .xlsx file via pipeline.py, I wanted it to be as fast as possible while gathering complete information.
A page with many people commenting, and because the review text is too long it gets put away, which means that almost 20 comments per page have their expand button.
Therefore, I need to use selenium to click the expand button and then use driver to fetch the complete comment. Common sense dictates that it takes a bit of time to load after the expand button is clicked, and I believe the time it takes depends on the speed of the network. So using WebDriverWait seems to be a wise choice here. After my practice, the default parameters timeout=10 and poll_frequency=0.5 seem to be too slow and error-prone. So I considered using the specifications of timeout=100 and poll_frequency=0.1.
However, the problem is that every time I run the project through the cmd statement scrapy crawl spider, there are always several comment crawls that are empty, and each time the location of the empty is different. I've thought about using time.sleep() to force a stop, but that would take a lot of time if every page did that, and while it's certainly a more useful way to get complete information. Also, it's looks not so elegant and a little bit clumsy in my opinion.
Have I express my question clearly?
-------------------------------add something--------------------------------
The exact meaning of I got somwhere empty is shown as the picture below.
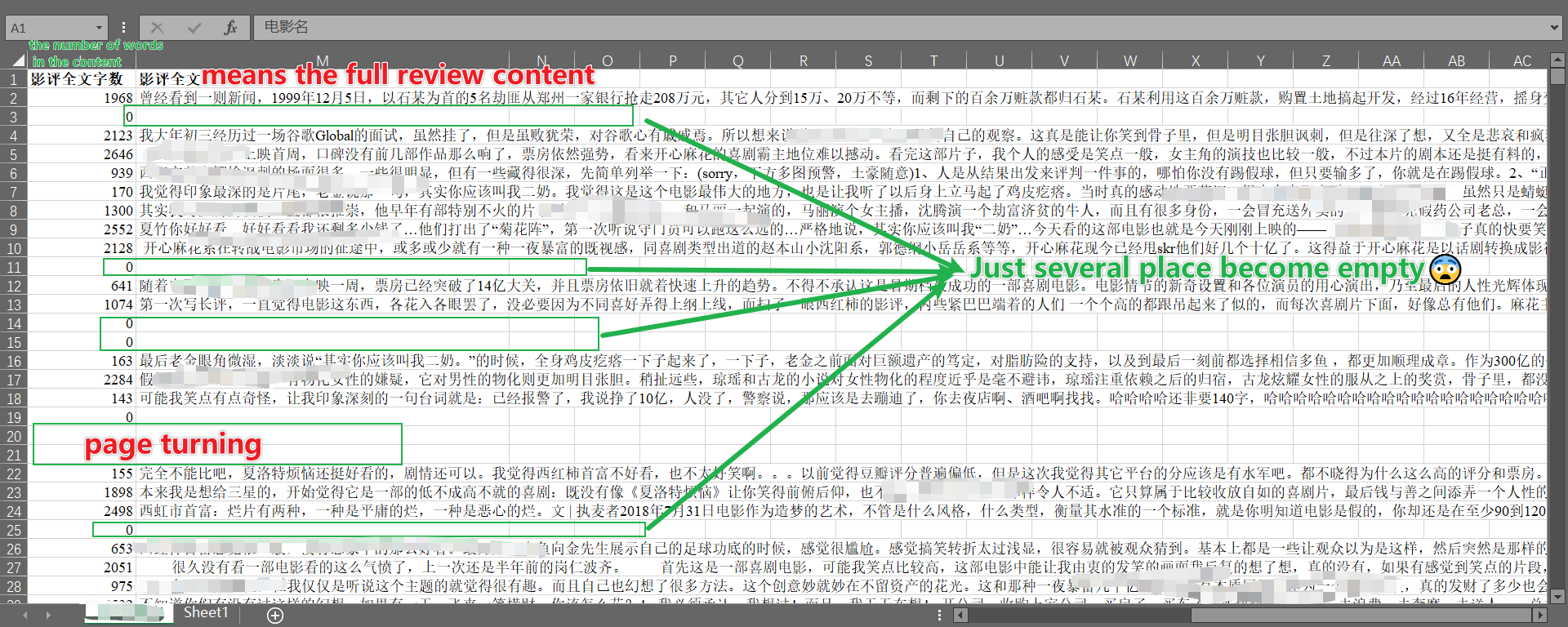
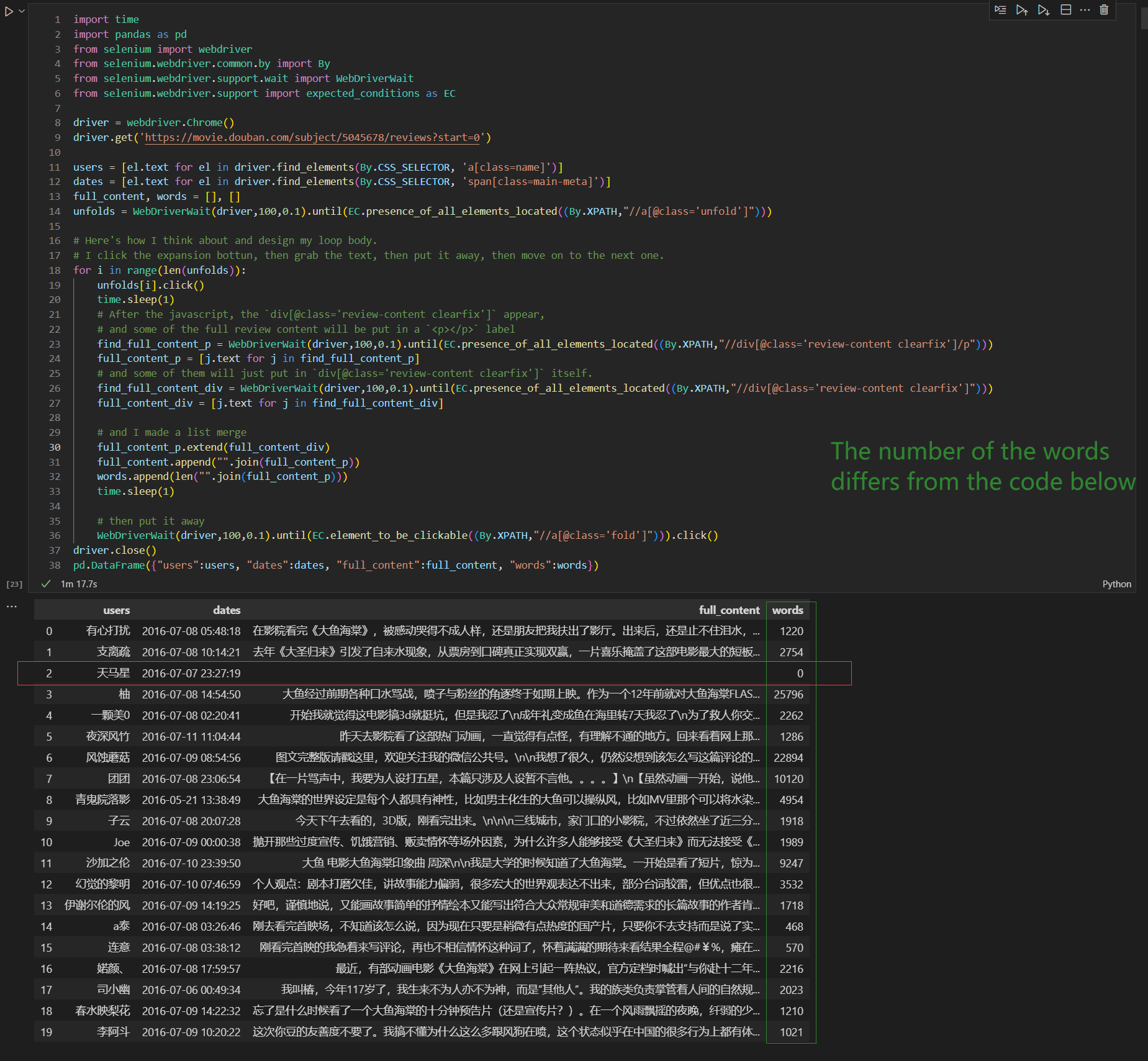
---------------------------add my code--------------------------2022/5/18
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://movie.douban.com/subject/5045678/reviews?start=0')
users = [el.text for el in driver.find_elements(By.CSS_SELECTOR, 'a[class=name]')]
dates = [el.text for el in driver.find_elements(By.CSS_SELECTOR, 'span[class=main-meta]')]
full_content, words = [], []
unfolds = WebDriverWait(driver,100,0.1).until(EC.presence_of_all_elements_located((By.XPATH,"//a[@class='unfold']")))
# Here's how I think about and design my loop body.
# I click the expansion bottun, then grab the text, then put it away, then move on to the next one.
for i in range(len(unfolds)):
unfolds[i].click()
time.sleep(1)
# After the javascript, the `div[@class='review-content clearfix']` appear,
# and some of the full review content will be put in a `<p></p>` label
find_full_content_p = WebDriverWait(driver,100,0.1).until(EC.presence_of_all_elements_located((By.XPATH,"//div[@class='review-content clearfix']/p")))
full_content_p = [j.text for j in find_full_content_p]
# and some of them will just put in `div[@class='review-content clearfix']` itself.
find_full_content_div = WebDriverWait(driver,100,0.1).until(EC.presence_of_all_elements_located((By.XPATH,"//div[@class='review-content clearfix']")))
full_content_div = [j.text for j in find_full_content_div]
# and I made a list merge
full_content_p.extend(full_content_div)
full_content.append("".join(full_content_p))
words.append(len("".join(full_content_p)))
time.sleep(1)
# then put it away
WebDriverWait(driver,100,0.1).until(EC.element_to_be_clickable((By.XPATH,"//a[@class='fold']"))).click()
driver.close()
pd.DataFrame({"users":users, "dates":dates, "full_content":full_content, "words":words})
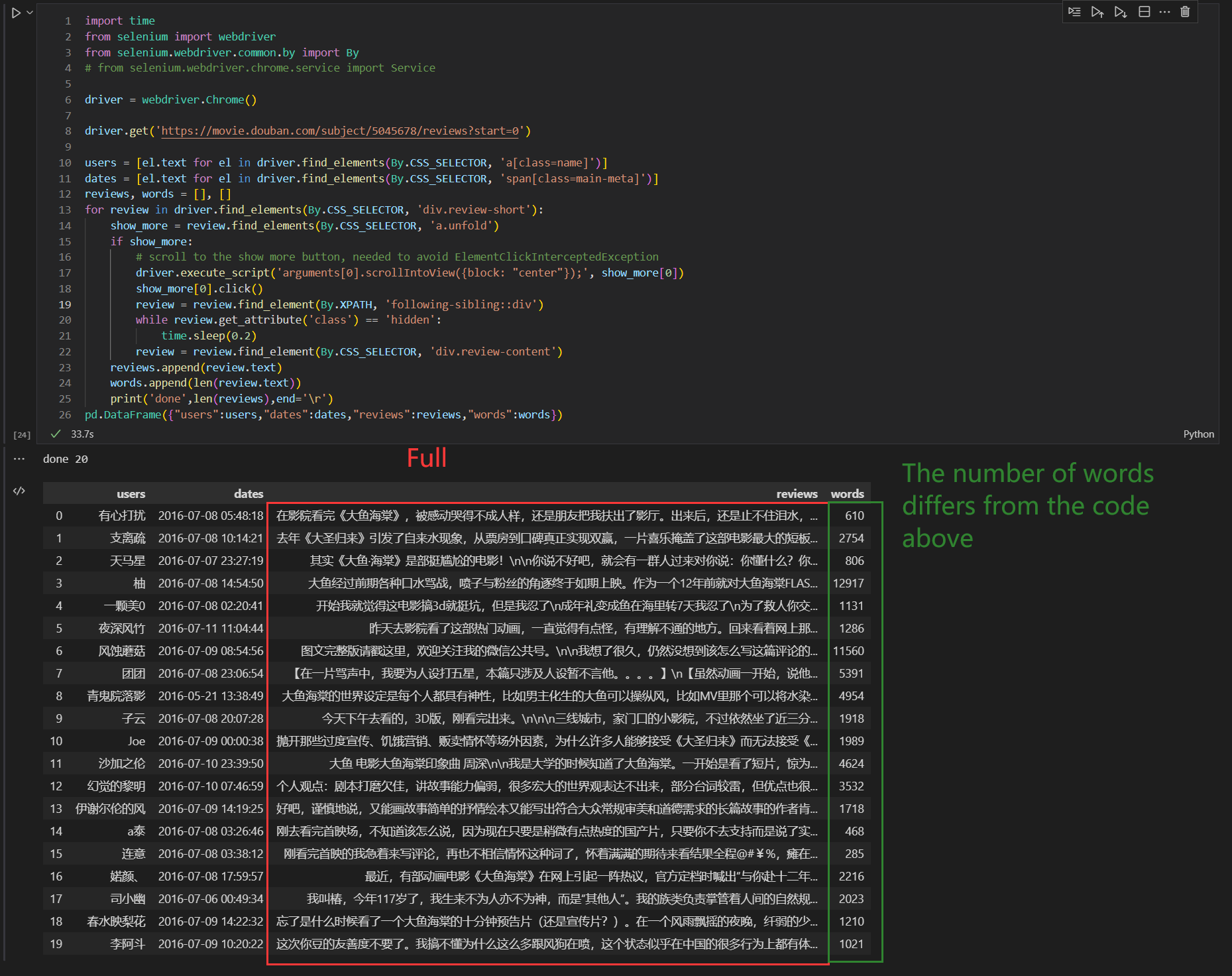
AND, this is the code of an expert I genuinely respect named sound wave.(This is slightly modified, the core code has not been changed)
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# from selenium.webdriver.chrome.service import Service
driver = webdriver.Chrome()
driver.get('https://movie.douban.com/subject/5045678/reviews?start=0')
users = [el.text for el in driver.find_elements(By.CSS_SELECTOR, 'a[class=name]')]
dates = [el.text for el in driver.find_elements(By.CSS_SELECTOR, 'span[class=main-meta]')]
reviews, words = [], []
for review in driver.find_elements(By.CSS_SELECTOR, 'div.review-short'):
show_more = review.find_elements(By.CSS_SELECTOR, 'a.unfold')
if show_more:
# scroll to the show more button, needed to avoid ElementClickInterceptedException
driver.execute_script('arguments[0].scrollIntoView({block: "center"});', show_more[0])
show_more[0].click()
review = review.find_element(By.XPATH, 'following-sibling::div')
while review.get_attribute('class') == 'hidden':
time.sleep(0.2)
review = review.find_element(By.CSS_SELECTOR, 'div.review-content')
reviews.append(review.text)
words.append(len(review.text))
print('done',len(reviews),end='\r')
pd.DataFrame({"users":users,"dates":dates,"reviews":reviews,"words":words})
CodePudding user response:
NEW
Added code for the site douban. To export the scraped data to a csv see the pandas code in the OLD section below
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
driver = webdriver.Chrome(service=Service('...'))
driver.get('https://movie.douban.com/subject/5045678/reviews?start=0')
users = [el.text for el in driver.find_elements(By.CSS_SELECTOR, 'a[class=name]')]
dates = [el.text for el in driver.find_elements(By.CSS_SELECTOR, 'span[class=main-meta]')]
reviews = []
for review in driver.find_elements(By.CSS_SELECTOR, 'div.review-short'):
show_more = review.find_elements(By.CSS_SELECTOR, 'a.unfold')
if show_more:
# scroll to the show more button, needed to avoid ElementClickInterceptedException
driver.execute_script('arguments[0].scrollIntoView({block: "center"});', show_more[0])
show_more[0].click()
review = review.find_element(By.XPATH, 'following-sibling::div')
while review.get_attribute('class') == 'hidden':
time.sleep(0.2)
review = review.find_element(By.CSS_SELECTOR, 'div.review-content')
reviews.append(review.text)
print('done',len(reviews),end='\r')
OLD
For the website you mentioned (imdb.com) in order to scrape the hidden content there is no need to click on the show more button because the text is already loaded in the HTML code, simply it is not shown on the site. So you can scrape all the comments in a single time. Code below stores users, dates and reviews in seprate lists, and finally save data to a .csv file.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
driver = webdriver.Chrome(service=Service(chromedriver_path))
driver.get('https://www.imdb.com/title/tt1683526/reviews')
# sets a maximum waiting time for .find_element() and similar commands
driver.implicitly_wait(10)
reviews = [el.get_attribute('innerText') for el in driver.find_elements(By.CSS_SELECTOR, 'div.text')]
users = [el.text for el in driver.find_elements(By.CSS_SELECTOR, 'span.display-name-link')]
dates = [el.text for el in driver.find_elements(By.CSS_SELECTOR, 'span.review-date')]
# store data in a csv file
import pandas as pd
df = pd.DataFrame(list(zip(users,dates,reviews)), columns=['user','date','review'])
df.to_csv(r'C:\Users\your_name\Desktop\data.csv', index=False)
To print a single review you can do something like this
i = 0
print(f'User: {users[i]}\nDate: {dates[i]}\n{reviews[i]}')
the output (truncated) is
User: dschmeding
Date: 26 February 2012
Wow! I was not expecting this movie to be this engaging. Its one of those films...