I'm reading a .csv file, that has dates as index and states as columns.
Something like this:
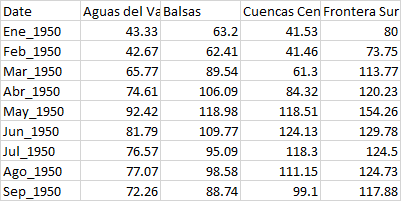
The dates go from January 1950 to April 2022, I want to vary the slicing of the dataframe, for example I want to take all of the Januaries and Februaries (from 1950 to 2022) so it will look something like this
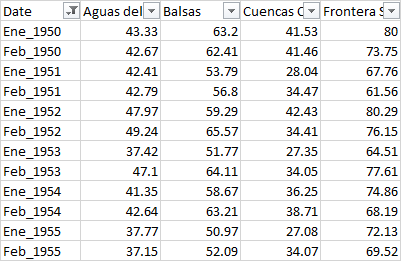
I know I can select every nth element with data.iloc[0::12], so I tried doing something like data.iloc[(0:1)::12] but it does not work.
How can I slice it the way I want it?
Thanks in advance
CodePudding user response:
You could use a startswith() option for this
df = df[(df['Date'].str.startswith('Ene')) | (df['Date'].str.startswith('Feb'))]
CodePudding user response:
It seems iloc supports lambda function. So if you want your way:
df.iloc[lambda x:(x.index % 12).isin([0,1])]
However, it seems better to use str.startswith for your cases
df[df.index.str.startswith('Ene') | df.index.str.startswith('Feb')]