I have some duplicate rows in my dataframe, the occurrences have Nan value in specific column 'Rank'. I want to remove duplicate, keep the fisrt occurrence with full data and replace Nan value with value from second occurrence when necessary.
| Name | Rank | City |
|---|---|---|
| Andre Ryan | NaN | London |
| Andre Ryan | 86 | Paris |
| Paul Nilson | 74 | LA |
| Paul Nilson | NaN | Chicago |
| ... | ...- | ... |
The goal
| Name | Rank | City |
|---|---|---|
| Andre Ryan | 86 | London |
| Paul Nilson | 74 | LA |
| ... | ... | ... |
CodePudding user response:
Here's one way to dedup by using groupby and agg on this example dataset:
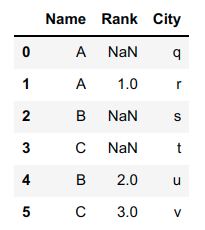
import pandas as pd
#create the test table
df = pd.DataFrame({
'Name':['A','A','B','C','B','C'],
'Rank':[None,1,None,None,2,3],
'City':['q','r','s','t','u','v'],
})
#groupby and agg to dedup
dedup_df = df.groupby('Name').agg(
Rank = ('Rank',lambda ranks: ranks.dropna().iloc[0]),
City = ('City','first'),
).reset_index()
dedup_df
Output
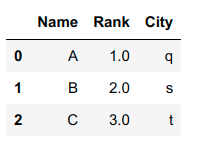
CodePudding user response:
You can try groupby and fill value then drop_duplicates
out = (df.assign(**df.groupby('Name')['Rank'].transform(lambda col: col.bfill().ffill()).to_frame())
.drop_duplicates('Name', keep='first'))
print(out)
Name Rank City
0 Andre Ryan 86.0 London
CodePudding user response:
Using first() in groupby returns the first non NaN value. Try this:
df.groupby('Name').first()