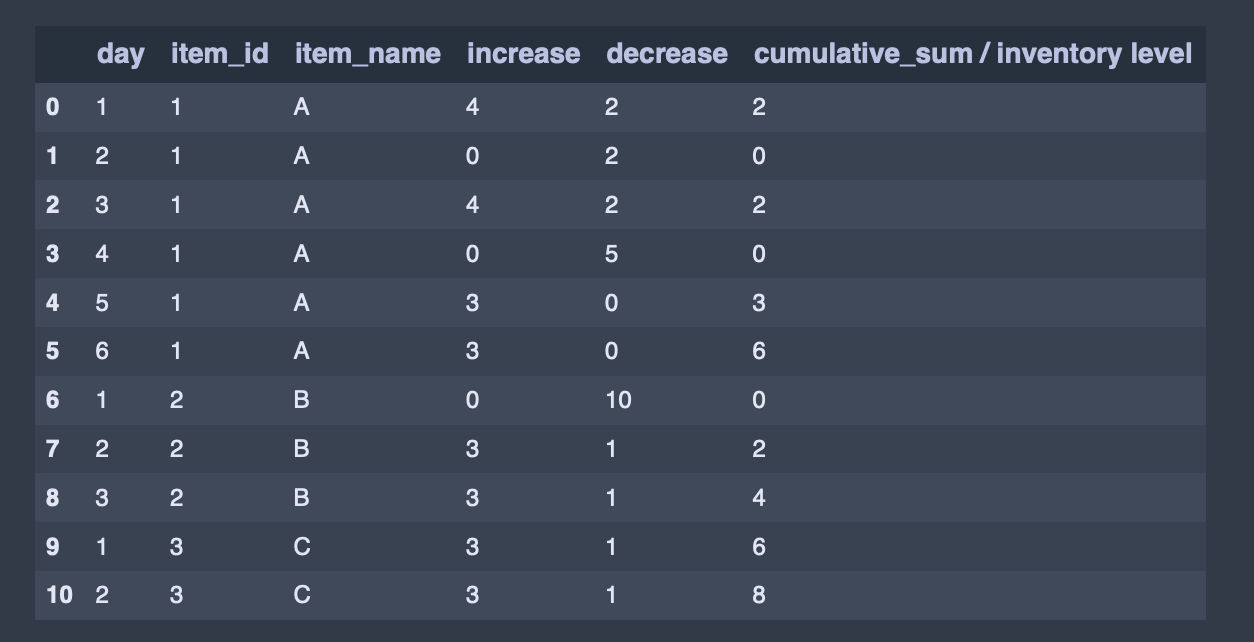
I have an inventory model where I have inputs increasing the inventory and outputs decreasing the inventory every day. The inventory cannot go below zero.
import numpy as np
import pandas as pd
day = [1, 2, 3, 4, 5, 6, 1, 2, 3, 1, 2]
item_id = [1, 1, 1, 1, 1, 1, 2, 2, 2, 3, 3]
item_name = ['A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'C', 'C']
increase = [4, 0, 4, 0, 3, 3, 0, 3, 3, 3, 3]
decrease = [2, 2, 2, 5, 0, 0, 5, 1, 1, 1, 1]
my_df = pd.DataFrame(list(zip(day, item_id, item_name, increase, decrease)),
columns=['day', 'item_id', 'item_name', 'increase', 'decrease'])
# my_df = my_df.set_index(['item_id', 'item_name'])
I'm working on calculating the inventory at the end of each day, for each item. Iterrows seems to be a good option for handling the non-negative requirement, but my method does not restart the inventory at zero for each new item.
inv_accumulator=[]
closing_inv_qty=0
for index, row in my_df.iterrows():
closing_inv_qty = np.maximum(closing_inv_qty row["increase"] - row["decrease"], 0)
inv_accumulator.append(closing_inv_qty)
my_df['cumulative_sum / inventory level'] = inv_accumulator
my_df
Rather than the output here: B should have inventory levels of 0, then 2, then 4 C should have inventory levels of 2, then 4
The groupby methods I've attempted don't seem to work with iterrows. Is there another way to calculate this?
CodePudding user response:
You can first calculate a net change and use group_by and cumsum to calculate the result.
my_df["net_change"] = my_df.eval("increase-decrease")
n = my_df.groupby("item_name")["net_change"].cumsum() < 0
my_df["inventory"] = my_df.groupby([n[::-1].cumsum(), "item_name"])["net_change"] \
.cumsum() \
.apply(lambda x: 0 if x < 0 else x)
CodePudding user response:
Looking also at Python Pandas iterrows() with previous values, the following seems to be correct:
my_df['change'] = my_df['increase'] - my_df['decrease']
inventory = []
for index, row in my_df.iterrows():
if my_df.loc[index, 'day']==1:
my_df.loc[index, 'beg_inventory'] = 0
my_df.loc[index, 'end_inventory'] = np.maximum(my_df.loc[index, 'change'], 0)
# my_df.loc[index, 'end_inventory'] = np.maximum(row['change'], 0) # same
else:
my_df.loc[index, 'beg_inventory'] = my_df.loc[index - 1, 'end_inventory']
my_df.loc[index, 'end_inventory'] = np.maximum(
my_df.loc[index - 1, 'end_inventory'] my_df.loc[index, 'change'], 0)
my_df