I'm a beginner so sorry in advance if I'm unclear :)
I have a .csv with 2 columns, doc_number and text. However, sometimes the rows start with the doc number (as they should) and sometimes it just starts with text from the previous row. All input is the type 'object'. There are also many empty rows between the inputs.
How can I make sure doc_number consists of all the numeric values (doc_numbers are random numbers of 8 digits) and text is the text, and remove the empty rows?
Example of what it looks like:
69353029, Hello. How are you doing?
What are you going to do tomorrow?
59302058, Tomorrow I have to go to work.
58330394, It's going to rain tomorrow
45801923, Yesterday it was sunny.
Next week it will also be sunny.
68403942, Thank you.
What it should look like:
_doc, _text
69353029, Hello. How are you doing? What are you going to do tomorrow?
59302058, Tomorrow I have to go to work.
58330394, It's going to rain tomorrow.
45801923, Yesterday it was sunny. Next week it will also be sunny.
68403942, Thank you.```
CodePudding user response:
Here's what I can think of when looking at the dataset. It looks like a CSV file which translates to an unnamed column (representing _doc) with mixed integers and strings and another unnamed column with strings (representing _text)
Since, it has to be csv, I created the following 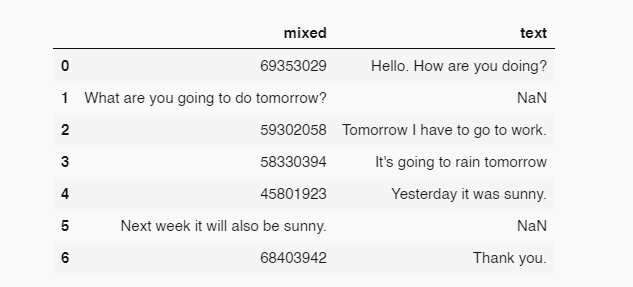
What we can do is separate the mixed column into two different columns m_numeric and m_text. This can be done by creating the m_numeric column using
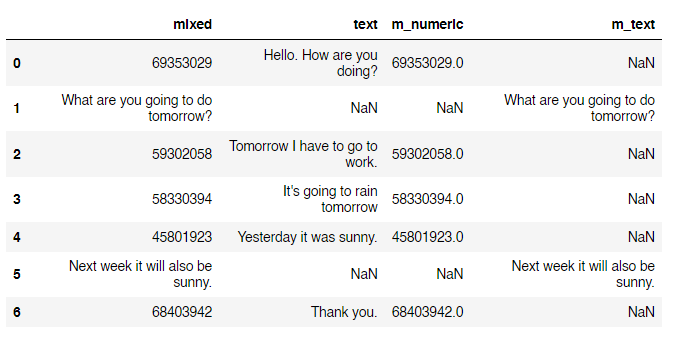
to_numeric(,errors='coerce') and non-numeric strings masked to m_text column as follows:
df['m_numeric'] = pd.to_numeric(df['mixed'], errors='coerce')
mask = df['m_numeric'].isna()
df.loc[mask, 'm_text'] = df.loc[mask, 'mixed']
We can now fill the NaN values in m-numeric using ffill from 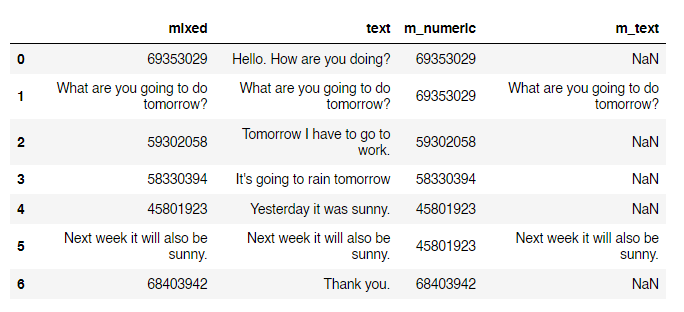
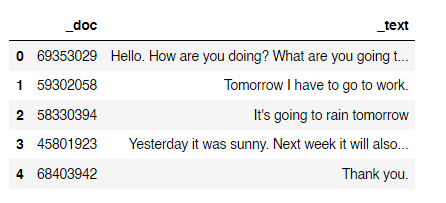
Now we have the final columns we need as text and m_numeric on which we can apply the pandas groupby() function. We groupby the m_numeric column and use .apply to join the strings in two rows separated by a space. Finally we can rename the column names to _doc and _text as follows:
df = df.groupby('m_numeric', sort= False)['text'].apply(' '.join).reset_index()
df = df.rename(columns= {'m_numeric' : '_doc',
'text' : '_text'})
Result:
Complete Code:
import pandas as pd
df = pd.read_csv('dummy.csv', header= None)
df.columns = ['mixed', 'text']
#separate column
df['m_numeric'] = pd.to_numeric(df['mixed'], errors='coerce')
mask = df['m_numeric'].isna()
df.loc[mask, 'm_text'] = df.loc[mask, 'mixed']
#replace nan values
df['m_numeric'] = df['m_numeric'].fillna(method='ffill')
df['m_numeric'] = df['m_numeric'].astype(int)
df['text'] = df['text'].fillna(df['m_text'])
#group by column
df = df.groupby('m_numeric', sort= False)['text'].apply(' '.join).reset_index()
df = df.rename(columns= {'m_numeric' : '_doc',
'text' : '_text'})
df
CodePudding user response:
also just learnning to panda, so maybe not the best solution:
import pandas as pd
import numpy as np
#reading .csv and naming the Headers, - you can choose your own namings here
df = pd.read_csv("text.csv", header=None, names = ["_doc","_text"])
# updating _text column emty cells with values from _doc
df["_text"] = np.where(df['_text'].isnull(),df["_doc"],df["_text"])
# change dtype to int (it will generate <NA> in strings) and back to str to aggregate later
df["_doc"] = df["_doc"].apply(pd.to_numeric, errors="coerce").astype("Int64").astype(str)
# aggregating rows if below value is <NA> and joining strings in col _text
df = df.groupby((df["_doc"].ne("<NA>")).cumsum()).agg({"_doc":"first","_text":" ".join}).reset_index(drop=True)
# converting back to int (if needed)
df["_doc"] = df["_doc"].astype(int)
print(df)
out:
_doc _text
0 69353029 Hello. How are you doing? What are you going ...
1 59302058 Tomorrow I have to go to work.
2 58330394 It's going to rain tomorrow
3 45801923 Yesterday it was sunny. Next week it will als...
4 68403942 Thank you.