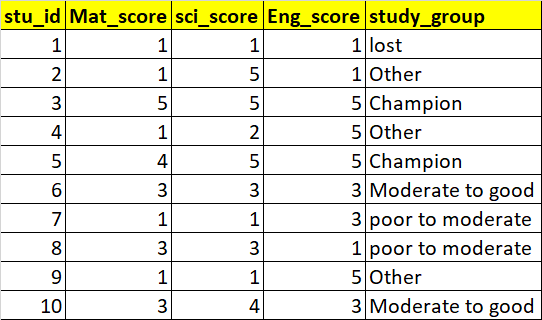
I have a dataframe like as shown below
stu_id,Mat_score,sci_score,Eng_score
1,1,1,1
2,1,5,1
3,5,5,5
4,1,2,5
5,4,5,5
6,3,3,3
7,1,1,3
8,3,3,1
9,1,1,5
10,3,4,3
df1 = pd.read_clipboard(sep=',')
I would like to create a new column called study_group based on below criteria
if a student has score of 5,5,5 and 4,4,4 or 4,5,5 or 4,5,4 or 5,4,4 then assign him to study_group called champion.
if a student has score of 1,1,1 or 1,2,1 or 2,2,1 or 1,1,2 or 2,2,2 or 2,1,1 etc, then assign to him to lost
if a student has a score of 3,3,3 or 3,2,3 or 3,4,3 or 3,5,3 etc, then assign to him to moderate to good
if a student has a score of 3,1,1 or 1,3,3 or 3,1,3 or 1,1,3 etc, then assign to him to poor to moderate
So, if the score doesn't fall under any of the ranges that I have given above, then they should be assigned to Other
So, I was trying something like below
study_group = []
for row in df1.iterrows():
rec = row[1]
m = rec['Mat_score']
s = rec['sci_score']
e = rec['Eng_score']
if (m in (4,5)) & (s in (4,5)) & (e in (4,5)):
study_group.append({rec['stu_id']:'Champion'})
elif (m in (1,2)) & (s in (1,2)) & (e in (1,2)):
study_group.append({rec['stu_id']:'Lost'})
elif (m in (3)) & (s in (2,3,4,5)) & (e in (3)):
study_group.append({rec['stu_id']:'moderate to good'})
elif (m in (1,3)) & (s in (1,3)) & (e in (1,3)):
study_group.append({rec['stu_id']:'Poor to moderate'})
else:
study_group.append({rec['stu_id']:'Other'})
But am not sure whether the above code is elegant and efficient. I have to write if-else for multiple different combinations
Is there any other efficient and elegant approach to do the above?
I expect my output to be like as below
CodePudding user response:
You can try np.select
score = df.filter(like='score')
df['study_group'] = np.select(
[score.isin([4,5]).all(axis=1),
score.isin([1,2]).all(axis=1),
(score[['Mat_score', 'Eng_score']].eq(3).all(axis=1) & score['sci_score'].ne(1)),
score.isin([1,3]).all(axis=1)],
['Champion',
'Lost',
'moderate to good',
'Poor to moderate'],
default='Other'
)
print(df)
stu_id Mat_score sci_score Eng_score study_group
0 1 1 1 1 Lost
1 2 1 5 1 Other
2 3 5 5 5 Champion
3 4 1 2 5 Other
4 5 4 5 5 Champion
5 6 3 3 3 moderate to good
6 7 1 1 3 Poor to moderate
7 8 3 3 1 Poor to moderate
8 9 1 1 5 Other
9 10 3 4 3 moderate to good