Workflow is :
- Read CSV file using Python's pandas library and get Variation Column
- Variation Column data is
Variation
----------
Color Family : Black, Size:Int:L
Color Family : Blue, Size:Int:M
Color Family : Red, Size:Int:Xl
- But I want to print this data in different column with sorted data and save its as a xlsx
Color Size
------- ------
Black L
Blue M
Red XL
My code is :
#spliting variation data
#taking variation column data in a var
get_variation = df_new['Variation']
#Splitting Column data
for part in get_variation:
format_part = str(part)
data = re.split(r'[:,]' , format_part)
df_new['Color'] = data[1]
df_new['Size'] = data[4]
But my output is coming as
Color Size
------ ------
Black L
Black L
Black L
CodePudding user response:
Try this
import re
df = pd.DataFrame({'Variation': ['Color Family : Black, Size:Int:L',
'Color Family : Blue, Size:Int:M',
'Color Family : Red, Size:Int:Xl']})
def func(x):
res = {}
# split on comma
for e in x.split(', '):
# and for each split piece, split into words
k, _, v = re.split('\W ', e)
res[k] = v
# build a dict and return
return res
# mapping the above function produces a list of dicts, so construct a df
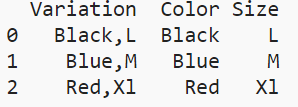
df = pd.DataFrame(map(func, df['Variation']))
print(df)
Color Size
0 Black L
1 Blue M
2 Red Xl
For Python 3.8 and above, the above function can be written as a one-liner using the walrus operator without losing much readability (imo):
df = pd.DataFrame({(kv:=re.split('\W ', e))[0]:kv[-1] for e in x.split(', ')} for x in df['Variation'])
print(df)
CodePudding user response:
Without mapping or iteration you can done using str .replace() function using pandas. Try this,
#replacing "Color Family : " to ""
df['Variation'] = df['Variation'].str.replace("Color Family : ","")
#replacing " Size:Int:" to ""
df['Variation'] = df['Variation'].str.replace(" Size:Int:","")
#splitting by , to seperate (Color and Size) then Expanding Columns
df[['Color', 'Size']] = df['Variation'].str.split(',', expand = True)
print(df)
The output will be,