I have two tables:
table "Person"
ID FirstName LastName
----------- ---------- ----------
1 Janez Novak
2 Matija Špacapan
3 Francka Joras
Table "UserList"
ID FullName
----- --------------------
1 Andrej Novak
2 Novak Peter Janez
3 Jana Novak
4 Andrej Kosir
5 Jan Balon
6 Francka Joras
7 France Joras
As a result, the query must return those IDs from both tables, that FirstName and Lastname from table Person exist in table UserList. The name and Lastname must be precisely the same. FullName in table UserList can include the middle name - which should be "ignored".
Match: Janez Novak = Janez Novak OR Novak Janez OR Janez Peter Novak
Not a match: Janez Novak <> Janeza Novak OR Jjanez Novak
Wanted results:
ID FirstName LastName ID WholeName
---- ---------- --------- ---- -------------------
1 Janez Novak 2 Novak Peter Janez
3 Francka Joras 6 Francka Joras
This is my query:
SELECT
A.ID
,A.FirstName
,A.LastName
,B.ID
,B.WholeName
FROM
dbo.UserList B
cross join dbo.Person A
WHERE
(
CHARINDEX('"' A.FirstName '"', '"' Replace(B.WholeName,' ','"') '"') > 0
AND CHARINDEX('"' A.LastName '"', '"' Replace(B.WholeName,' ','"') '"') > 0
)
The query works OK when there are not many records in the tables.
But my tables have: "Person" -> 400k and "UserList" -> 14k records.
Is my approach to finding a solution OK, or is there any other more efficient way to do that? Thank you.
BR
CodePudding user response:
Your schema is broken :p
There are various heuristis for doing the matching, but I expect you'll be able to find counterexamples to break whatever you try. For example what about the four people: Peter Smith, Pete Smith, Peter Smithson, and Pete Smithson?
Here's a %LIKE% approach, which I'd expect to be slow.
SELECT p.ID, p.FirstName, p.LastName, u.ID, u.FullName,
CASE WHEN COUNT(*) OVER (PARTITION BY p.ID) > 1 THEN 0 ELSE 1 END AS MatchIsUnique
FROM Person p
INNER JOIN UserList u
ON u.FullName LIKE p.FirstName '%'
AND u.LastName LIKE '%' p.LastName
Here's a string manipulation approach based on the assumption that the space character is the delimiter.
SELECT p.ID, p.FirstName, p.LastName, u.ID, u.FullName,
CASE WHEN COUNT(*) OVER (PARTITION BY p.ID) > 1 THEN 0 ELSE 1 END AS MatchIsUnique
FROM Person p
INNER JOIN UserList u
ON p.FirstName = SUBSTRING(@FullName, 0, CHARINDEX(' ', @Fullname))
AND p.LastName = SUBSTRING(@FullName, LEN(@FullName) - CHARINDEX(' ', REVERSE(@Fullname)) 1, CHARINDEX(' ', REVERSE(@Fullname)))
Probably also quite slow. Maybe you could speed it up by adding
SUBSTRING(@FullName, 0, CHARINDEX(' ', @Fullname))andSUBSTRING(@FullName, LEN(@FullName) - CHARINDEX(' ', REVERSE(@Fullname)) 1, CHARINDEX(' ', REVERSE(@Fullname)))
as computed columns and indexing them.
CodePudding user response:
Create tables
create table persons (
id int IDENTITY(1,1) PRIMARY KEY,
FirstName nvarchar(32) NOT NULL,
LastName nvarchar(32) NOT NULL
);
create table users (
id int IDENTITY(1,1) PRIMARY KEY,
FullName nvarchar(32) NOT NULL
);
Sample data
INSERT INTO persons (FirstName, LastName)
values
('Janez','Novak'),
('Matija','Špacapan'),
('Francka','Joras');
INSERT INTO users (FullName)
VALUES
('Andrej Novak'),
('Novak Peter Janez'),
('Jana Novak'),
('Andrej Kosir'),
('Jan Balon'),
('Francka Joras'),
('France Joras');
Query (matching names)
SELECT p.id, p.FirstName, p.LastName, u.id as user_id, u.FullName
FROM persons p, users u
WHERE
u.name LIKE CONCAT(p.fname, '%', p.lname)
OR
u.name LIKE CONCAT(p.lname, '%', p.fname)
Output
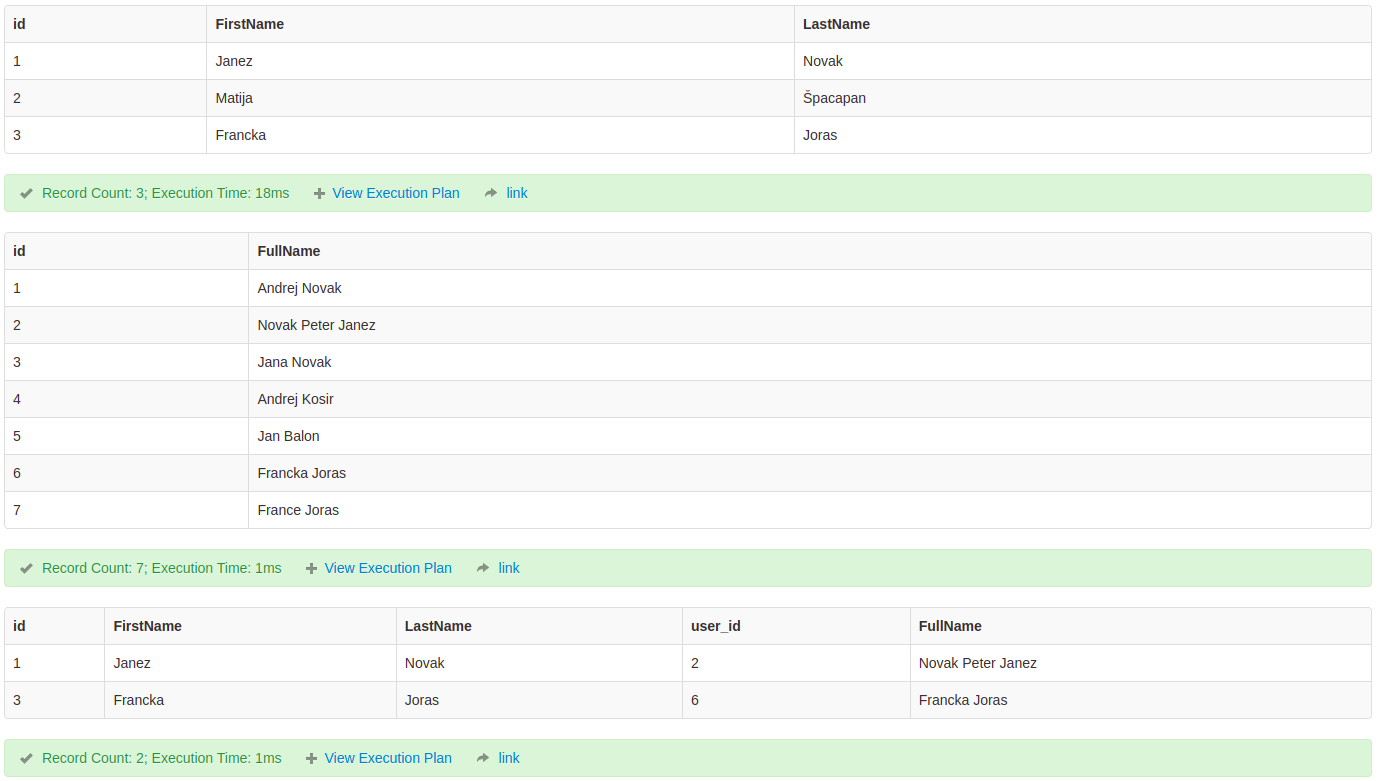
Running example SQL Fiddle
Above example link is of MySQL & the code is working fine on SQL server