I am working with a really messy dataset for my master's thesis and I need some help with copying values from one column to other columns.
What I need to do is the following:
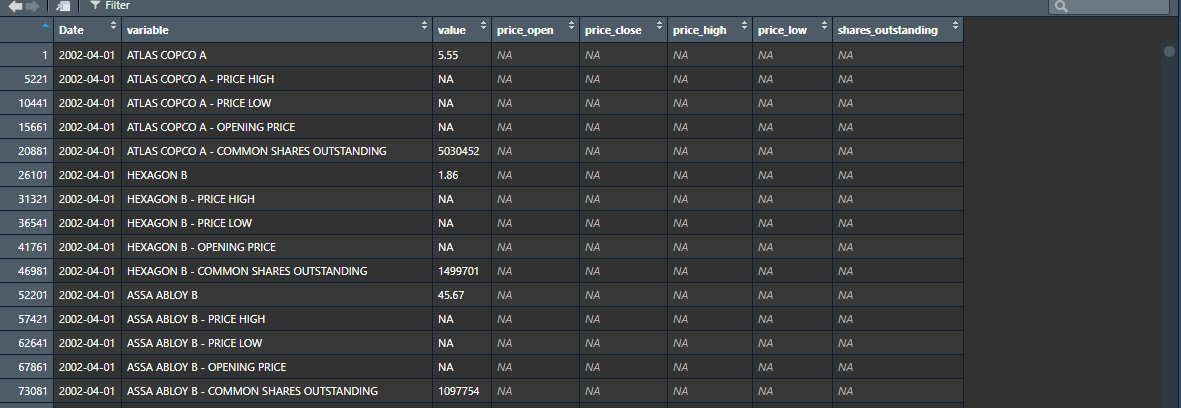
- I need the value from row 1 to be copied to the column price_close in the same row.
- I need the value from row 2 to be copied to the column price_high in row 1
- I need the value from row 3 to be copied to the column price_low in row 1
- I need the value from row 4 to be copied to the column price_open in row 1
- I need the value from row 5 to be copied to the column shares_outstanding in row 1
This needs to be done for all companies and for all dates. Hence, I need to do the same procedure for the next company. Meaning:
- I need the value from row 5 to be copied to the column price_close in the same row.
- I need the value from row 6 to be copied to the column price_high in row 5
- I need the value from row 7 to be copied to the column price_low in row 5
- I need the value from row 8 to be copied to the column price_open in row 5
- I need the value from row 9 to be copied to the column shares_outstanding in row 5
The dataset is too large to be able to do this by hand. However, I imagine that this is possible using a loop in R, since the "copying" follows the same pattern throughout the dataset. If that's the case, I would really appreciate some guidance to solve this problem. Thanks!
In the picture attached, you can see how my data looks like.
CodePudding user response:
What you are describing is converting your data from "long format to wide format". Searching that phrase will turn up lots of ways to accomplish this in R. Here's one, you could use pivot_wider() from tidyr, like this:
(edited to use separate() as suggested by @Axeman)
library(dplyr)
library(tidyr)
df %>%
separate(col = "variable", into = c("company", "metric"), sep = " - ") %>%
pivot_wider(id_cols = c("company", "date"), names_from = "metric", values_from = "value")
#> company date Price Close High Price Price Low Opening price
#> 1 Company 1 2022-01-01 5.5 6.0 5.0 5.0
#> 2 Company 2 2022-01-01 3.5 7.0 8.0 1.0
#> 3 Company 1 2022-01-02 5.4 5.9 4.9 4.8
#> Common Shares Outstanding
#> 1 1000
#> 2 5000
#> 3 1000
data:
df <- data.frame(variable = c("Company 1 - Price Close",
"Company 1 - High Price",
"Company 1 - Price Low",
"Company 1 - Opening price",
"Company 1 - Common Shares Outstanding",
"Company 2 - Price Close",
"Company 2 - High Price",
"Company 2 - Price Low",
"Company 2 - Opening price",
"Company 2 - Common Shares Outstanding",
"Company 1 - Price Close",
"Company 1 - High Price",
"Company 1 - Price Low",
"Company 1 - Opening price",
"Company 1 - Common Shares Outstanding"),
date = c(rep("2022-01-01", 10), rep("2022-01-02", 5)),
value = c(5.5, 6, 5, 5, 1000,
3.5, 7, 8, 1, 5000,
5.4, 5.9, 4.9, 4.8, 1000))
Created on 2022-05-23 by the reprex package (v2.0.1)