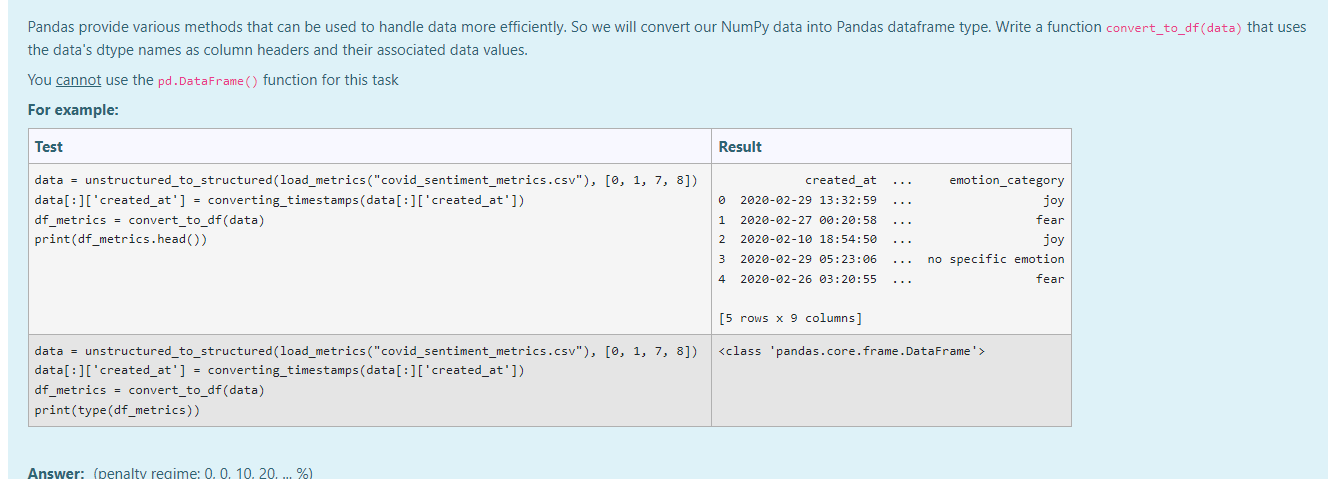
I have a question in an assessment where i have to convert NumPy data into Pandas dataframe type. It also should use the data's dtype names as column headers.
I cannot use the pd.DataFrame() function for this task and there has been a clue given where I am supposed to still use pandas methods.
This is the code i have so far -
def convert_to_df(data):
"converting numpy array into dataframe"
far = data.tolist()
return pd.Series(far).to_frame()
which does convert it to a DataFrame ,giving this with the test:
0
0 (2020-02-29 13:32:59, 1.23375E 18, 0.67, 0.293...
1 (2020-02-27 00:20:58, 1.23282E 18, 0.442, 0.38...
2 (2020-02-10 18:54:50, 1.22694E 18, 0.577, 0.42...
3 (2020-02-29 05:23:06, 1.23362E 18, 0.514, 0.41...
4 (2020-02-26 03:20:55, 1.23251E 18, 0.426, 0.37...
im just confused on how to then get the headers in order. My output when i run test code is meant to look like this.
created_at ... emotion_category
0 2020-02-29 13:32:59 ... joy
1 2020-02-27 00:20:58 ... fear
2 2020-02-10 18:54:50 ... joy
3 2020-02-29 05:23:06 ... no specific emotion
4 2020-02-26 03:20:55 ... fear
[5 rows x 9 columns]
I have attached a screenshot of the question so you can see the test codes and the wording. Hope someone can help !
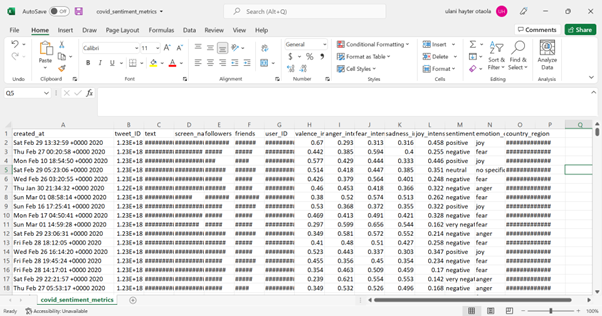
the data im using looks like this
CodePudding user response:
You can use pandas series instead, what I would do is convert each column in the numpy array to a Series, for example, I have the following numpy array:
data = np.array([[1, 2, 3], [4, 5, 6]])
I will use a for loop to create series for each column:
series = []
for i in range(data.shape[1]):
series.append(pd.Series(data[:,i], name="Serie_" str(i)))
Finally, concatenate these series to one dataframe:
pd.concat([series[i] for i in range(data.shape[1])], axis=1)
The result:
Serie_0 Serie_1 Serie_2
0 1 2 3
1 4 5 6
I hope this helps.