I have the below dataframe and I would like to select the column based on the value in the 'AGE' column and perform a math calculation based on the value in that column for that row.
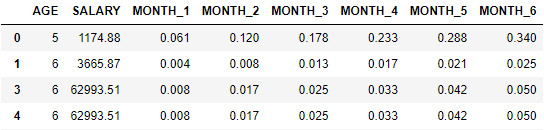
For example, for row 0 the AGE value is 5, therefore I need to pick value from the column 'MONTH_5' which is 0.288 and multiply it by the SALARY for that row, which is 1174.88 and populate the result (1174.88 * 0.288) in a new column named 'Final_Value'. Similarly, for row 1, the AGE value is 6, therefore I need to pick value from column 'MONTH_6' for that row (which is 0.025) and multiply it by the SALARY for that row, which is 3665.87 and populate the result (3665.87* 0.025) in a new column named 'Final_Value'. I need to do this for every row in the dataframe.
I tried to apply the logic using lambda, however, I'm unable to figure out how to select the column, based on the values in AGE column for each row in the dataframe.
def calculate_sal(age, salary):
return_val = 0
month_col_name = 'MONTH_' str(age)
return_val = my_df[month_col_name]
return return_val * salary
my_df['Final_Value'] = my_df.apply(lambda row: calculate_sal(row['AGE'],row['salary']), axis=1)
When I'm trying the above code, I'm getting the following error:
"ValueError: Wrong number of items passed 235, placement implies 1"
How can I achieve this? Please advise.
Thank you!
CodePudding user response:
def calculate_sal(df, age):
for index, row in df.iterrows():
if row["AGE"] == age:
row["Final_Value"] = row["AGE"] * row["MONTH_" str(age)]
elif row["AGE"] == age:
row["Final_Value"] = row["AGE"] * row["MONTH_" str(age)]
elif:
...
return
CodePudding user response:
IIUC, you can also try np.arange like Indexing and selecting data
idx, cols = pd.factorize('MONTH_' df['AGE'].astype(str))
df['col'] = df.reindex(cols, axis=1).to_numpy()[np.arange(len(df)), idx]