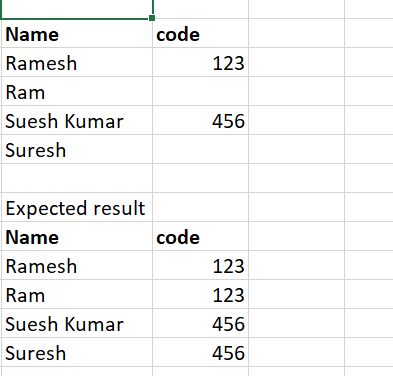
Name Code
Ramesh 1234
Ramesh kumar
Suresh 4532
Sur
This is the sample data ,if name contains similar string it should populate the code
Expected result:
Name Code
Ramesh 1234
Ramesh kumar 1234
Suresh 4532
Sur 4532
CodePudding user response:
Your question does not match your example and your two examples do not match. Here is an answer assuming that your first example is actually what you want - that you want to match the first three letters of the names to the code. Matching names can be a lot more complicated if you have many similar names, so this is not a particularly general solution, but it works for your example.
import numpy as np
import pandas as pd
# Create test dataframe
test = pd.DataFrame({'Name':['Ramesh','Ramesh kumar','Suresh','Sur'],
'Code':[1234,np.nan,4532,np.nan]})
# Create dictionary that maps first three letters of Name to value in Code
dfmap = test[~np.isnan(test['Code'])]
dictmap = {x['Name'][:3]:x['Code'] for i,x in dfmap.iterrows()}
# Map the first three letters of the name to a new column
test['mapping'] = test['Name'].str[:3].map(dictmap)
# Write over nans in the Code column with the values in the new column
test.loc[np.isnan(test['Code']),'Code'] = test.loc[np.isnan(test['Code']),'mapping']
# Remove temporary mapping column
test = test.drop(columns='mapping')
CodePudding user response:
Considering your example and without further explanation, the .ffill() method could be enough:
df = (pd.DataFrame({'name' : ['Ramesh', 'Ramesh Kumar', 'Ram', 'Sur', 'Suresh Kumar', 'Suresh'],
'code' : [123,np.NaN,np.NaN,456,np.NaN,np.NaN]
}))
df['filled'] = df.code.ffill(axis = 0)
df
| index | name | code | filled |
|---|---|---|---|
| 0 | Ramesh | 123.0 | 123.0 |
| 1 | Ramesh Kumar | NaN | 123.0 |
| 2 | Ram | NaN | 123.0 |
| 3 | Sur | 456.0 | 456.0 |
| 4 | Suresh Kumar | NaN | 456.0 |
| 5 | Suresh | NaN | 456.0 |