One column in a data frame has names, each name is repeated at least 10 times so there are many names. In another column, I have numbers. I want to add two new columns, one displaying the lowest number for a specific name (that appears in the NUMBERS column), and the second displaying the highest number.
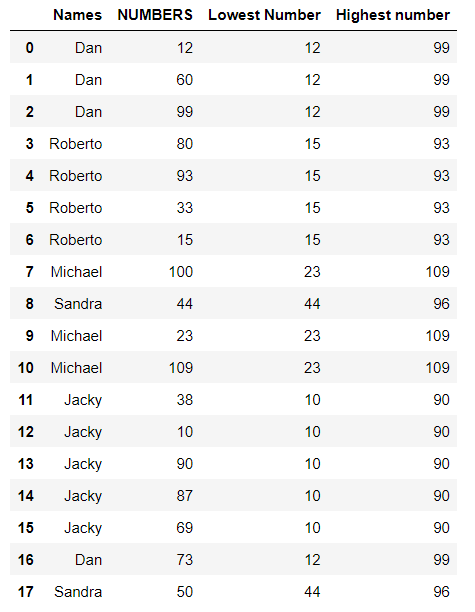
This is a dummy data that is similar to my real data, just to make my question more clear :
CodePudding user response:
Sample data:
df = pd.DataFrame({'name':['a','b','a','b','b','c','a','c'],
'val':[1,2,3,4,5,6,7,8]})
Using groupby, transform and apply:
df['min'] = df.groupby('name')[['val']].transform(lambda g: g.min())
df['max'] = df.groupby('name')[['val']].transform(lambda g: g.max())
CodePudding user response:
IIUC, you can try
out = df.merge(df.groupby('Names')['NUMBERS']
.agg(**{'Lowest Number': 'min', 'Highest Number': 'max'}).reset_index())