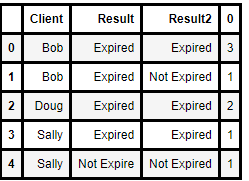
I am fairly new with Python but would like to learn it. Basically I would like to get a value count by grouping. My dataset looks something like that below. I would like to sort by Client and get a count of "Expired" and "Not Expired" for each person. Then I would like to write to an excel file giving each unique "Client" its own sheet. I have the write to Excel file code but am completely lost on getting the groupby and value counts to work properly.
with pd.ExcelWriter("Test.xlsx") as writer: for client, data in summary2.groupby('client'): data.to_excel(writer, sheet_name = client)
My dataframe looks something like this:
Client | Result | Result2 |
Bob | Expired | Expired |
Bob | Expired | Not Expire |
Sally | Not Expire | Not Expire |
Bob | Expired | Expired |
Sally | Expired | Expired |
Doug | Expired | Expired |
Bob | Expired | Expired |
Doug | Expired | Expired |
What I would like is:
Client | Result | Result2 |
Bob | Expired | Expired |
Bob | Expired | Not Expire |
Bob | Expired | Expired |
Bob | Expired | Expired |
n Expired | 4 | 3 |
n Not Expire| 0 | 2 |
Sally | Not Expire | Not Expire |
Sally | Expired | Expired |
n Expired | 1 | 1
n Not Expire| 1 | 1
Doug | Expired | Expired |
Doug | Expired | Expired |
n Expired | 2 | 2
n Not Expire| 0 | 0
CodePudding user response:
Here is one way bring the columns (result, result2) as rows and then using groupby to take the count
df2=df.melt('Client')
df2.groupby(['Client','variable','value'])['value'].count()
Client variable value value
Bob Result Expired 4
Bob Result2 Expired 3
Bob Result2 Not Expire 1
Doug Result Expired 2
Doug Result2 Expired 2
Sally Result Expired 1
Sally Result Not Expire 1
Sally Result2 Expired 1
Sally Result2 Not Expire 1
CodePudding user response:
Here is the groupby
sample1 = pd.DataFrame(sample.groupby(['Client', 'Result', 'Result2']).size()).reset_index()