I'm using beautifulSoup to extract some data off of a wiki, but I can only get the first data of a specific column. If my understanding of for-loops is correct, it should loop through everything in the table. I tested this by printing "t" to the console and it shows all the data in HTML format. Is there a reason why this is happening?
from bs4 import BeautifulSoup
import requests, csv
import pandas as pd
wiki_url = "https://en.wiktionary.org/wiki/Appendix:Mandarin_Frequency_lists/1-1000"
table_id = "wikitable"
response = requests.get(wiki_url)
soup = BeautifulSoup(response.text, 'html.parser')
#table = soup.find('table', class_="wikitable")
table = soup.find_all('table', class_="wikitable")
with open('chinesewords.csv', 'w', encoding='utf8', newline='') as c:
writer = csv.writer(c)
writer.writerow(["simplified, pinyin"])
for t in table:
simplified = t.find('span', class_="Hans").text
print(simplified)
The output:
一
(I apologize in advance if I didn't follow the rules of StackOverflow posting, as this is my first time posting a question)
CodePudding user response:
Make your life easier and try pandas.read_html().
Here's an example:
import requests
import pandas as pd
table = (
pd
.read_html(
requests
.get(
"https://en.wiktionary.org/wiki/Appendix:Mandarin_Frequency_lists/1-1000"
).text,
flavor="lxml"
)[0]
)
table.to_csv("mandarin_frequency_lists.csv", index=False)
Output:
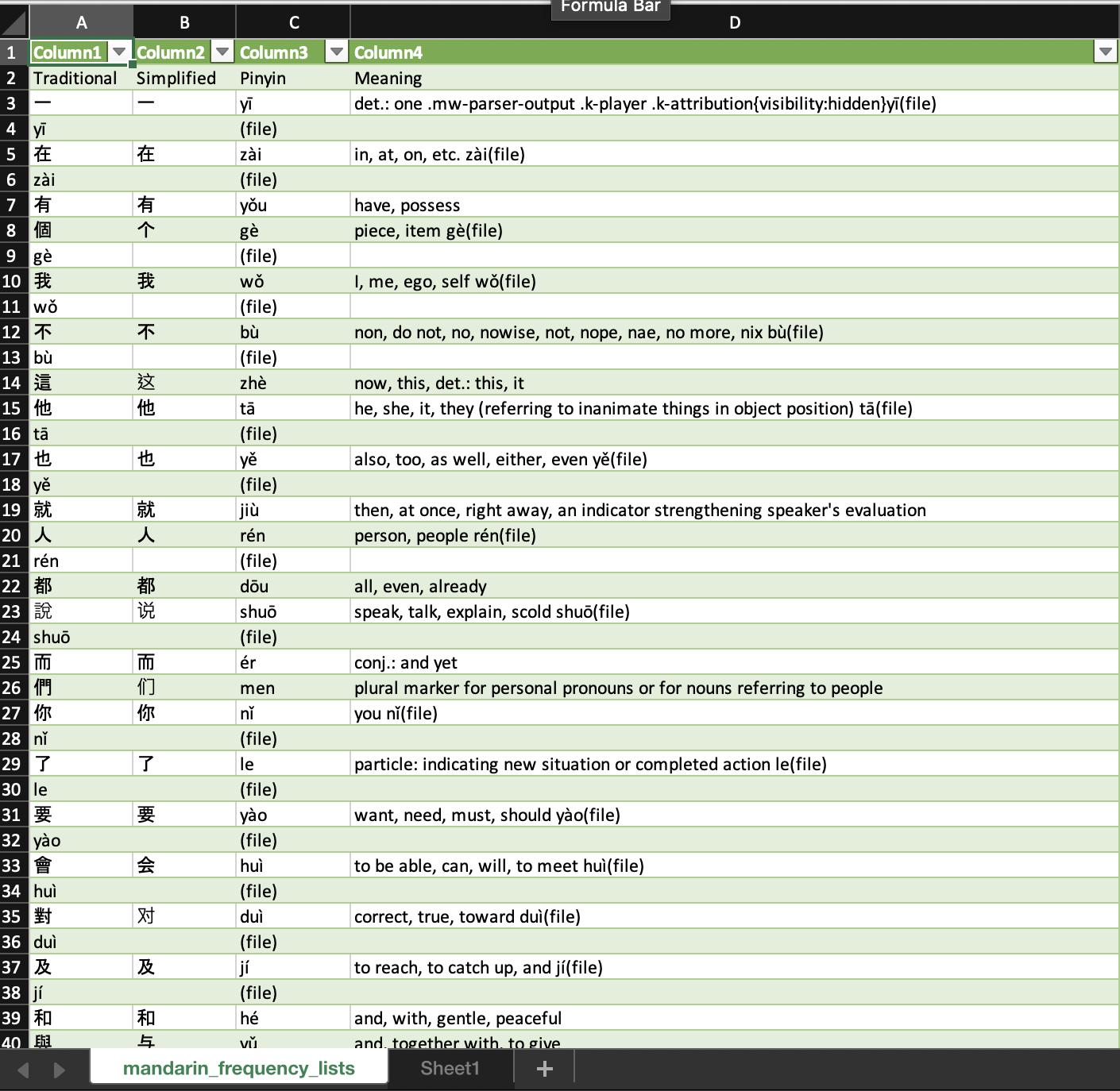
CodePudding user response:
If you mean data from one column from the table, the following code is enough. I hope I helped:
from bs4 import BeautifulSoup
import requests, csv
import pandas as pd
wiki_url = "https://en.wiktionary.org/wiki/Appendix:Mandarin_Frequency_lists/1-1000"
response = requests.get(wiki_url)
soup = BeautifulSoup(response.text, 'html.parser')
table_column = soup.find_all('span', class_="Hans")
with open('chinesewords.csv', 'w', encoding='utf32', newline='') as c:
writer = csv.writer(c)
writer.writerow(["simplified, pinyin"])
for t in table_column:
simplified = t.text
print(simplified)
writer.writerow(simplified)