I have written relatively complicated query that returns 7k rows in 1-2s.
But when I add where condition as follows, it takes 10-20s
WHERE exists (select 1 from BOM where CustomerId = @__customerId_0 and Code = queryAbove.Code)
I've checked the execution plan and the problem is not BOM from where clause itself (it is indexed and returns ccs 100 rows).
According to actual execution plan, 90% of the cost consumed by subquery that is fast without this where condition.
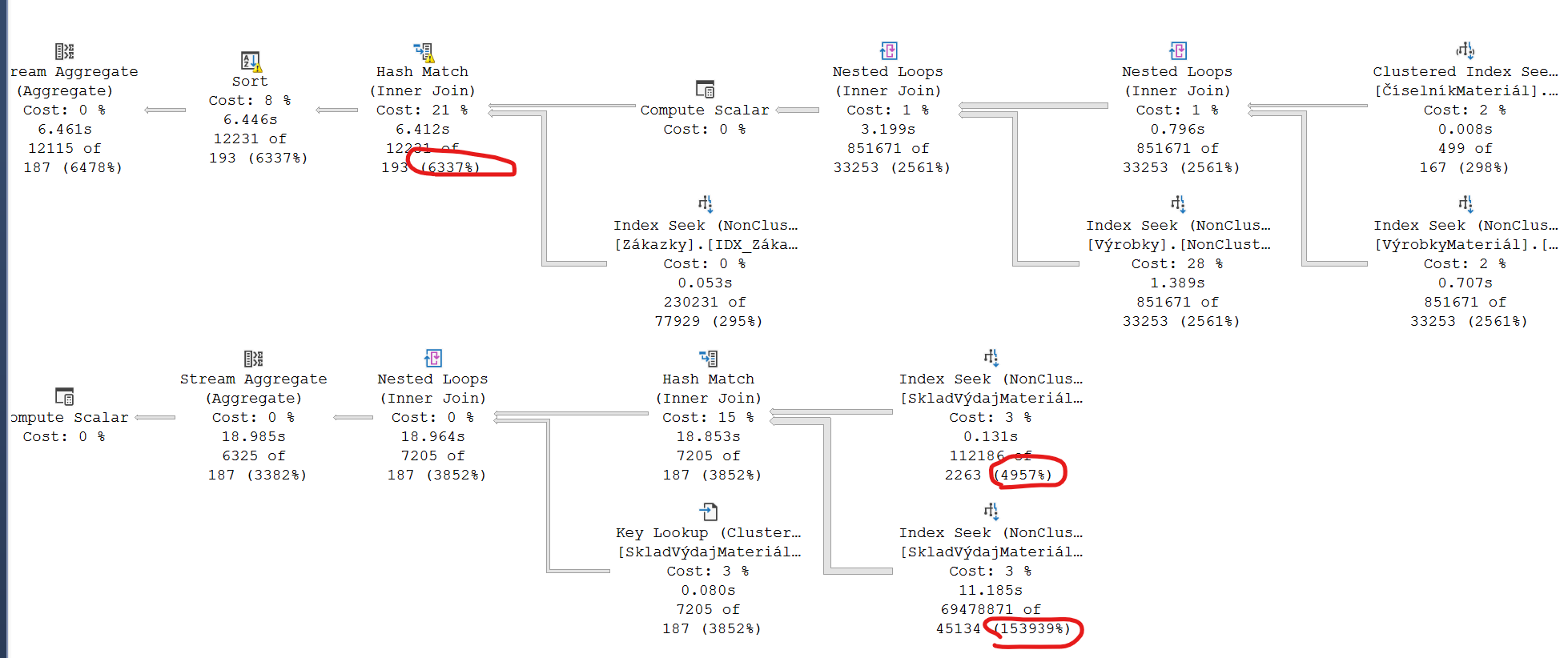
The question is, why are the estimates from execution plan so inaccurate? Is this "normal", or something is off with my database
I have tried sp_updatestats and rebuild indexes - it didn't have any effect.
As per comment, here is the query and execution plan: https://www.brentozar.com/pastetheplan/?id=HkKgCWGuq and my indexes:
ALTER TABLE [dbo].[ČíselníkMateriál] ADD CONSTRAINT [PK_SkladČíselníkMateriál] PRIMARY KEY CLUSTERED
( [KódMateriálu] ASC )
ALTER TABLE [dbo].[SkladVýdajMateriál] ADD CONSTRAINT [PK_SkladVýdajMateriál] PRIMARY KEY CLUSTERED
( [ID] ASC )
ALTER TABLE [dbo].[Výrobky] ADD CONSTRAINT [Výrobky_PK] PRIMARY KEY CLUSTERED
( [ID] ASC )
ALTER TABLE [dbo].[VýrobkyMateriál] ADD CONSTRAINT [PK_VýrobkyMateriál] PRIMARY KEY CLUSTERED
( [ID] ASC )
ALTER TABLE [dbo].[Zákazky] ADD CONSTRAINT [Zákazky_PK] PRIMARY KEY CLUSTERED
( [ID] ASC )
CREATE UNIQUE NONCLUSTERED INDEX [UQ_ČíselníkMateriál_ID] ON [dbo].[ČíselníkMateriál]
( [ID] ASC ) WITH (IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 80, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [IX_SkladVýdajMateriál_IDVýrobky] ON [dbo].[SkladVýdajMateriál]
( [IDVýrobky] ASC )
CREATE NONCLUSTERED INDEX [IX_SkladVýdajMateriál_KódMateriálu] ON [dbo].[SkladVýdajMateriál]
( [KódMateriálu] ASC )
CREATE NONCLUSTERED INDEX [IX_Výrobky_Status] ON [dbo].[Výrobky]
( [Status] ASC )
CREATE NONCLUSTERED INDEX [NonClusteredIndex-20220527-162213] ON [dbo].[Výrobky]
( [ID] ASC ) INCLUDE([IDZákazky],[Množstvo]) WITH (DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
CREATE NONCLUSTERED INDEX [VýrobkyIDZákazky] ON [dbo].[Výrobky]
( [IDZákazky] ASC ) INCLUDE([Množstvo])
CREATE NONCLUSTERED INDEX [IX_VýrobkyMateriál_IdMateriálu] ON [dbo].[VýrobkyMateriál]
( [IdMateriálu] ASC ) INCLUDE([IdVýrobku],[Množstvo],[ID])
CREATE NONCLUSTERED INDEX [IX_VýrobkyMateriál_IdVýrobku] ON [dbo].[VýrobkyMateriál]
( [IdVýrobku] ASC ) INCLUDE([IdMateriálu],[Množstvo],[ID])
CREATE NONCLUSTERED INDEX [IDX_Zákazky_Status] ON [dbo].[Zákazky]
( [Status] ASC ) INCLUDE([ID])
CodePudding user response:
why are the estimates so inaccurate?
In my experience, JOIN too many tables that might let estimates more and more inaccurate in one query, because of that estimates rows histogram statistics and formula SQL Server Join Estimation using Histogram Coarse Alignment
I would try to rewrite your query first, but I didn't know the logic of your tables.
There are two Key Lookup that might cost more logical read from non-cluster index Lookup to cluster index, so I would suggest modifying there are two indexes.
using IdVýrobku column be the key instead of INCLUDE column inIX_VýrobkyMateriál_IdMateriálu index, because IdVýrobku is JOIN key.
CREATE NONCLUSTERED INDEX [IX_VýrobkyMateriál_IdMateriálu] ON [dbo].[VýrobkyMateriál]
([IdMateriálu] ASC,[IdVýrobku])
INCLUDE([Množstvo],[ID]);
Add include Množstvo column on IX_SkladVýdajMateriál_IDVýrobky which add data in leaf page might reduce Key Lookup to cluster index from IX_SkladVýdajMateriál_IDVýrobky non-clustered index.
CREATE NONCLUSTERED INDEX [IX_SkladVýdajMateriál_IDVýrobky] ON [dbo].[SkladVýdajMateriál]
( [IDVýrobky] ASC )
INCLUDE (Množstvo);
CodePudding user response:
D-Shih is right. When you JOIN many tables, wrong estimates get multiplied into really wrong estimates. But the first wrong estimates (506 customer/materials and not 65) is due to the distribution of data in isys.MaterialCustomers.
I'm not sure if 65 is the average number of materials per customer or just the average in that particular bucket, but you end up with 8x the number of lookups SQL Server estimated, and from there it just compounds.
SQL Server thinks it only needs to do 65 iterations on the initial query, but in fact has to do 500. Had it known in advance, maybe it would have chosen another plan. If you look for customerIds with fewer materials, you should get a faster execution, but also inaccurate estimates because now you're looping over fewer than 65 materials.
One way to fix you query is to
SELECT Code
INTO #CodesToConsider
FROM isys.MaterialCustomers
WHERE CustomerId = @__customer_id;
(... your huge select ...)
AS [s]
INNER JOIN #CodesToConsider ctc ON (s.MaterialCode = ctc.Code);
The temp-table will provide SQL Server with statistics on how many Codes to consider and then recompile the second part if those statistics change. They need to change by a bit, so I'm a bit unsure if 65 -> 506 is enough, but that's for you to find out.