I cannot find any explanation about numpy.where function.
I have dataframe:
activity count
0 1 25
1 2 38
2 3 49
3 4 55
4 5 61
5 6 74
6 7 82
7 8 98
8 9 103
9 10 4084
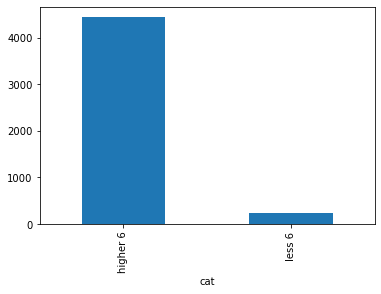
and I want to count values:
- for rows where activity < 6, sum count (so for index < 5)
- for rows where activity =< 6, sum count ( so for index =< 5)
and crate a charts for this two condition which shows sum count values. I have tried:
under_total = df[df.activity < 6]
under_total.loc['under_total'] = under_total.sum(axis = 0)
or
df['below_expectations'] = np.where(df['actibity'] < 6, df['activity'], df['hoursActive'])
but it seems I dont get it somewhere. I would be greatful for help.
CodePudding user response:
You can compute a group for 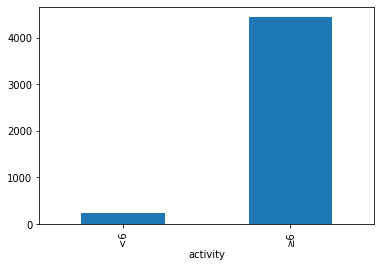
intermediate data:
(df.groupby(df['activity'].lt(6)
.map({True: '<6', False: '≥6'}))
['count'].sum()
)
output:
activity
<6 228
≥6 4441
Name: count, dtype: int64
CodePudding user response:
Use