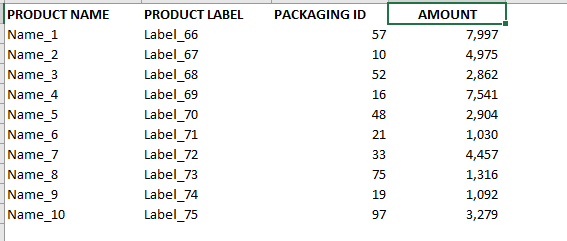
I want to perform a pandas merge with different rules. I have a sales table below with PRODUCT NAMES, PRODUCT LABEL and PACKAGING ID.
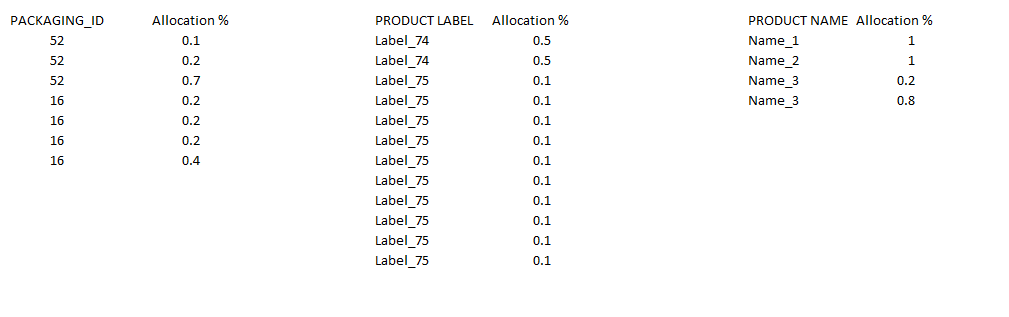
Mapping Tables
My goal is to obtain the following table:
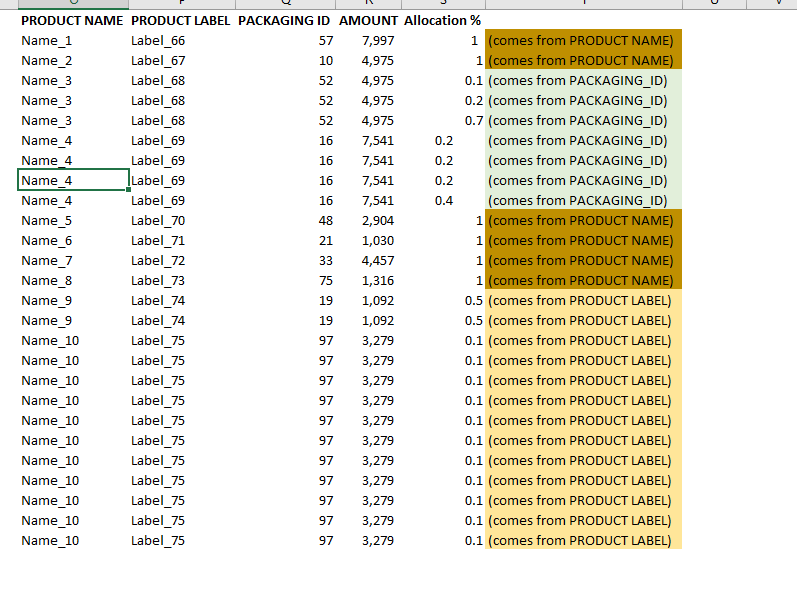
The only condition is that we have priorities:
- If there is a mapping on PACKAGING ID -> Use that allocation
- If there is not mapping on PACKAGING ID, then use PRODUCT LABEL
- At the last resource, if there is nothing on both, use PRODUCT NAME.
Thank you.
Using pd.merge creates multiple columns on the dataframe...and i want the results in the same columns and aligned to the table.
merged_df = pd.merge(database, mapping.package_id, left_on="Package ID", right_on="Package ID", how="left")
merged_df_2 = pd.merge(merged_df, mapping.product_label, left_on="Product Label", right_on="Product_Label", how="left")
merged_df_3 = pd.merge(merged_df_2, mapping.product_name, left_on="Product Name", right_on="Product_Name", how="left")
return merged_df_3
CodePudding user response:
Here's a way to do what you're asking using join():
df = dfSales.join(dfPack.set_index('PACKAGING ID'), on='PACKAGING ID')
df = df.join(dfLabel.set_index('PRODUCT LABEL'), on='PRODUCT LABEL', rsuffix='_LABEL')
df = df.join(dfName.set_index('PRODUCT NAME'), on='PRODUCT NAME', rsuffix='_NAME').reset_index(drop=True)
pack = df['Allocation %'].notna()
df.loc[~pack, 'Allocation %'] = df['Allocation %_LABEL']
df.loc[~(pack | df['Allocation %_LABEL'].notna()), 'Allocation %'] = df['Allocation %_NAME']
df = df.drop(columns=['Allocation %_LABEL', 'Allocation %_NAME']).drop_duplicates().reset_index(drop=True)
Input:
dfSales:
PRODUCT NAME PRODUCT LABEL PACKAGING ID AMOUNT
0 Name_1 Label_66 57 123
1 Name_2 Label_67 10 123
2 Name_3 Label_68 52 123
3 Name_4 Label_69 16 123
4 Name_5 Label_70 48 123
5 Name_6 Label_71 21 123
6 Name_7 Label_72 33 123
7 Name_8 Label_73 75 123
8 Name_9 Label_74 19 123
9 Name_10 Label_75 97 123
dfPack:
PACKAGING ID Allocation %
0 52 0.1
1 52 0.2
2 52 0.7
3 16 0.2
4 16 0.2
5 16 0.2
6 16 0.4
dfLabel:
PRODUCT LABEL Allocation %
0 Label_74 0.5
1 Label_74 0.5
2 Label_75 0.1
3 Label_75 0.1
4 Label_75 0.1
5 Label_75 0.1
6 Label_75 0.1
7 Label_75 0.1
8 Label_75 0.1
9 Label_75 0.1
10 Label_75 0.1
11 Label_75 0.1
dfName:
PRODUCT NAME Allocation %
0 Name_1 1.0
1 Name_2 1.0
2 Name_3 0.2
3 Name_3 0.8
Output:
PRODUCT NAME PRODUCT LABEL PACKAGING ID AMOUNT Allocation %
0 Name_1 Label_66 57 123 1.0
1 Name_2 Label_67 10 123 1.0
2 Name_3 Label_68 52 123 0.1
3 Name_3 Label_68 52 123 0.2
4 Name_3 Label_68 52 123 0.7
5 Name_4 Label_69 16 123 0.2
6 Name_4 Label_69 16 123 0.4
7 Name_5 Label_70 48 123 NaN
8 Name_6 Label_71 21 123 NaN
9 Name_7 Label_72 33 123 NaN
10 Name_8 Label_73 75 123 NaN
11 Name_9 Label_74 19 123 0.5
12 Name_10 Label_75 97 123 0.1
If you want to eliminate rows with null allocation, you can add the following as a final line in the code:
df = df[df['Allocation %'].notna()].reset_index(drop=True)
Output:
PRODUCT NAME PRODUCT LABEL PACKAGING ID AMOUNT Allocation %
0 Name_1 Label_66 57 123 1.0
1 Name_2 Label_67 10 123 1.0
2 Name_3 Label_68 52 123 0.1
3 Name_3 Label_68 52 123 0.2
4 Name_3 Label_68 52 123 0.7
5 Name_4 Label_69 16 123 0.2
6 Name_4 Label_69 16 123 0.4
7 Name_9 Label_74 19 123 0.5
8 Name_10 Label_75 97 123 0.1
CodePudding user response:
import pandas as pd
import numpy as np
# recreated data
df = pd.DataFrame({'PRODUCT NAME': ["Name_" str(x) for x in np.arange(1, 11, 1)],
'PRODUCT LABEL':["Label_" str(x) for x in np.arange(66, 76, 1)],
'PACKAGING ID': [57, 10, 52, 16, 48, 21, 33, 75, 19, 97],
'AMOUNT': [7997, 4974, 2862, 7541, 2904, 1030, 4457, 1316, 1092, 3279]})
m_pack = pd.DataFrame({'PACKAGING_ID': [52]*3 [16]*4,
'Allocation %': [.1, .2, .7, .2, .2, .2, .4]})
m_name = pd.DataFrame({'PRODUCT NAME': ["Name_1", "Name_2", "Name_3", "Name_4"],
'Allocation %': [1, 1, .2, .8]})
m_label = pd.DataFrame([["Label_74", .5]]*2 [["Label_75", .1]]*10, columns=["PRODUCT LABEL", "Allocation %"])
Merging, as per your example (with a slight difference):
# merge as your did, but setting index first so that these columns are not carried across
df2 = pd.merge(df, m_pack.set_index("PACKAGING_ID"), left_on="PACKAGING ID", right_index=True, how="left")
df2 = pd.merge(df2, m_label.set_index("PRODUCT LABEL"), left_on="PRODUCT LABEL", right_index=True, how="left")
df2 = pd.merge(df2, m_name.set_index("PRODUCT NAME"), left_on="PRODUCT NAME", right_index=True, how="left")
Creating the final dataframe with the data from df2:
# final df not including the "Allocation" columns.
final_df = df2.loc[:,~df2.columns.str.contains("Allocation")]
# fillna for each, progressing in order of merge/priority.
final_df["Allocation %"] = df2["Allocation %_x"].fillna(df2["Allocation %_y"]).fillna(df2["Allocation %"])
# add the final column of where the allocation came from.
final_df["Comes from"] = np.where(df2["Allocation %_x"].notna(), "(comes from PACKAGING_ID)",
np.where(df2["Allocation %_y"].notna(), "(comes from PRODUCT LABEL)",
"(comes from PRODUCT NAME)"))
final_df.reset_index(inplace=True)
final_df
# index PRODUCT NAME PRODUCT LABEL PACKAGING ID AMOUNT Allocation % Comes from
# 0 0 Name_1 Label_66 57 7997 1.0 (comes from PRODUCT NAME)
# 1 1 Name_2 Label_67 10 4974 1.0 (comes from PRODUCT NAME)
# 2 2 Name_3 Label_68 52 2862 0.1 (comes from PACKAGING_ID)
# 3 2 Name_3 Label_68 52 2862 0.2 (comes from PACKAGING_ID)
# 4 2 Name_3 Label_68 52 2862 0.7 (comes from PACKAGING_ID)
# 5 3 Name_4 Label_69 16 7541 0.2 (comes from PACKAGING_ID)
# 6 3 Name_4 Label_69 16 7541 0.2 (comes from PACKAGING_ID)
# 7 3 Name_4 Label_69 16 7541 0.2 (comes from PACKAGING_ID)
# 8 3 Name_4 Label_69 16 7541 0.4 (comes from PACKAGING_ID)
# 9 4 Name_5 Label_70 48 2904 NaN (comes from PRODUCT NAME)
# 10 5 Name_6 Label_71 21 1030 NaN (comes from PRODUCT NAME)
# 11 6 Name_7 Label_72 33 4457 NaN (comes from PRODUCT NAME)
# 12 7 Name_8 Label_73 75 1316 NaN (comes from PRODUCT NAME)
# 13 8 Name_9 Label_74 19 1092 0.5 (comes from PRODUCT LABEL)
# 14 8 Name_9 Label_74 19 1092 0.5 (comes from PRODUCT LABEL)
# 15 9 Name_10 Label_75 97 3279 0.1 (comes from PRODUCT LABEL)
# 16 9 Name_10 Label_75 97 3279 0.1 (comes from PRODUCT LABEL)
# 17 9 Name_10 Label_75 97 3279 0.1 (comes from PRODUCT LABEL)
# 18 9 Name_10 Label_75 97 3279 0.1 (comes from PRODUCT LABEL)
# 19 9 Name_10 Label_75 97 3279 0.1 (comes from PRODUCT LABEL)
# 20 9 Name_10 Label_75 97 3279 0.1 (comes from PRODUCT LABEL)
# 21 9 Name_10 Label_75 97 3279 0.1 (comes from PRODUCT LABEL)
# 22 9 Name_10 Label_75 97 3279 0.1 (comes from PRODUCT LABEL)
# 23 9 Name_10 Label_75 97 3279 0.1 (comes from PRODUCT LABEL)
# 24 9 Name_10 Label_75 97 3279 0.1 (comes from PRODUCT LABEL)
You will notice there were a couple of missing values in the Allocation % column, this is because there was no data for it in the PRODUCT NAME mapping. It looks like you have set them to 1, but I wasn't sure if I could do that. If that is the solution, add another .fillna(1) to the .fillna line.