I have about 200 CSV files and I need to combine them on specific columns. Each CSV file contains 1000 filled rows on specific columns. My file names are like below:
csv_files = [en_tr_translated0.csv, en_tr_translated1000.csv, en_tr_translated2000.csv, ......... , en_tr_translated200000.csv]
My csv file columns are like below:
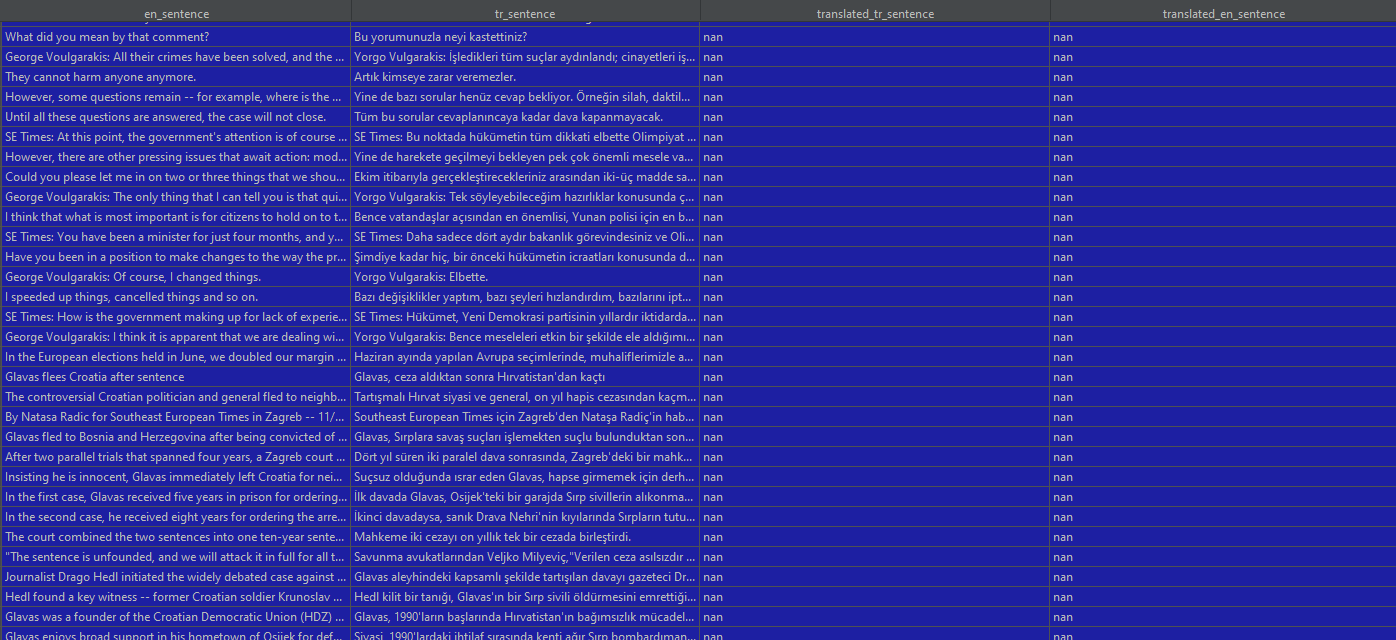
The two first columns are prefilled up to same 200.000 rows/sentences in the all csv files. My each en_tr_translated{ }.csv files contains 1000 translated sentences related with their file name. For example:
en_tr_translated1000.csv file contains translated sentences from 0 to 1000th row, en_tr_translated2000.csv file contains translated sentences from 1000th to 2000th row etc. Rest is nan/empty. Below is an example image from en_tr_translated3000.csv file.

I want to copy/merge/join the rows to have one full csv file that contains all the translated sentences. I tried the below code:
out = pd.read_csv(path 'en_tr_translated0.csv', sep='\t', names=['en_sentence', 'tr_sentence', 'translated_tr_sentence', 'translated_en_sentence'], dtype=str, encoding='utf-8', low_memory=False)
##
i = 1000
for _ in tqdm(range(200000)):
new = pd.read_csv(path f'en_tr_translated{i}.csv', sep='\t', names=['en_sentence', 'tr_sentence', 'translated_tr_sentence', 'translated_en_sentence'], dtype=str, encoding='utf-8', low_memory=False)
out.loc[_, 'translated_tr_sentence'] = new.loc[_, 'translated_tr_sentence']
out.loc[_, 'translated_en_sentence'] = new.loc[_, 'translated_en_sentence']
if _ == i:
i = 1000
Actually, it works fine but my problem is, it takes 105 HOURS!!
Is there any faster way to do this? I have to do this for like 5 different datasets and this is getting very annoying.
Any suggestion is appreciated.
CodePudding user response:
Your input files have one row of data exactly as one row in the file, correct? So it would probably be even faster if you don't even use pandas. Although if done correctly 200.000 should be still very fast no matter if using pandas or not.
For doing it without: Just open each file, move to the fitting index, write 1000 lines to the output file. Then move on to next file. You might have to fix headers etc. and look out that there is no shift in the indices, but here is an idea of how to do that:
with open(path 'en_tr_translated_combined.csv', 'w') as f_out: # open out file in write modus
for filename_index in tqdm(range(0, 201000, 1000)): # iterate over each index in steps of 1000 between 0 and 200000
with open(path f'en_tr_translated{filename_index}.csv') as f_in: # open file with that index
for row_index, line in enumerate(f_in): # iterate over its rows
if row_index < filename_index: # skip rows until you reached the ones with content in translation
continue
if row_index > filename_index 1000: # close the file if you reached the part where the translations end
break
f_out.write(line) # for the inbetween: copy the content to out file
CodePudding user response:
I would load all the files, drop the rows that are not fully filled, and afterwards concatenate all of the dataframes.
Something like:
dfs = []
for ff in Path('.').rglob('*.csv'):
dfs.append((pd.read_csv(ff, names=['en_sentence', 'tr_sentence', 'translated_tr_sentence', 'translated_en_sentence'], dtype=str, encoding='utf-8', low_memory=True).dropna())
df = pd.concat(dfs)