I have this dataframe:
# A tibble: 6 x 28
Full.Name `1_2019` `1_2020` `10_2019` `10_2020` `11_2019` `11_2020` `12_2019` `12_2020` `2_2019` `2_2020`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 A. Patrick Beh~ 0.0342 0.0697 0.280 0.827 0.145 1.22 0.640 0.314 0.838 0.984
2 Aaron P. Graft -0.540 -0.871 -0.931 -0.783 -0.669 -0.824 -0.751 -0.725 -0.718 -0.785
3 Aaron P. Jagdf~ -0.540 -0.871 -0.931 -0.783 -0.669 -0.824 -0.751 -0.725 -0.718 -0.785
4 Adam H. Schech~ -0.540 -0.871 -0.931 -0.783 -0.669 1.54 -0.751 -0.725 -0.718 -0.785
5 Adam P. Symson -0.540 0.399 0.654 2.77 0.445 -0.824 -0.751 -0.725 1.68 0.882
6 Adena T. Fried~ 0.0143 0.662 1.59 1.62 0.682 2.80 1.75 1.62 0.714 -0.785
# ... with 17 more variables: `3_2019` <dbl>, `3_2020` <dbl>, `4_2019` <dbl>, `4_2020` <dbl>, `5_2019` <dbl>,
# `5_2020` <dbl>, `6_2019` <dbl>, `6_2020` <dbl>, `7_2019` <dbl>, `7_2020` <dbl>, `8_2019` <dbl>,
# `8_2020` <dbl>, `9_2019` <dbl>, `9_2020` <dbl>, Entity <chr>, Ticker.Symbol <chr>, Ra <dbl>
Now I want to visualize the data in one plot to show the difference between each column from column 2 to 25. In case that is not possible, maybe there is another way to visualize it in a table or something similar. Any help is appreciated.
Only basic descriptive statistics is needed. But I cannot make it work.
this is my dput() output:
structure(list(Full.Name = c("A. Patrick Beharelle", "Aaron P. Graft",
"Aaron P. Jagdfeld", "Adam H. Schechter", "Adam P. Symson", "Adena T. Friedman"
), `1_2019` = c(0.0341902759485775, -0.539575700110418, -0.539575700110418,
-0.539575700110418, -0.539575700110418, 0.0142678462243068),
`1_2020` = c(0.0697387174146791, -0.871245532931706, -0.871245532931706,
-0.871245532931706, 0.398794559560348, 0.662210282447589),
`10_2019` = c(0.279752225085438, -0.930707945269455, -0.930707945269455,
-0.930707945269455, 0.654418468290524, 1.58684577038463),
`10_2020` = c(0.82666306332842, -0.783180767805507, -0.783180767805507,
-0.783180767805507, 2.76920795289669, 1.6170818813176), `11_2019` = c(0.145135675475795,
-0.669456555191454, -0.669456555191454, -0.669456555191454,
0.44485587027092, 0.682163146063833), `11_2020` = c(1.21972285616297,
-0.82365835659611, -0.82365835659611, 1.53636250690043, -0.82365835659611,
2.79869924784045), `12_2019` = c(0.640269916000742, -0.750782313148717,
-0.750782313148717, -0.750782313148717, -0.750782313148717,
1.74811390688025), `12_2020` = c(0.314454813694554, -0.724720606267494,
-0.724720606267494, -0.724720606267494, -0.724720606267494,
1.62304608327639), `2_2019` = c(0.838072458618591, -0.717924356584493,
-0.717924356584493, -0.717924356584493, 1.68263757489192,
0.713989777980387), `2_2020` = c(0.984031718342916, -0.785473730983455,
-0.785473730983455, -0.785473730983455, 0.882246006656001,
-0.785473730983455), `3_2019` = c(0.965132606814049, -0.835520830003005,
-0.835520830003005, -0.835520830003005, -0.122525648211637,
0.33206859521239), `3_2020` = c(0.90882717808108, -0.83705737889734,
-0.83705737889734, 0.781853755755377, -0.83705737889734,
0.192308082442538), `4_2019` = c(0.629959737882837, 5.16531443882641,
-0.726770300860967, -0.726770300860967, -0.726770300860967,
0.446061732631307), `4_2020` = c(0.590233135876032, -0.814080668963169,
-0.814080668963169, 0.478779659301492, 0.333105256116742,
0.309370374908192), `5_2019` = c(0.366887998375501, -0.895404727952587,
-0.895404727952587, -0.895404727952587, 1.02257894232926,
0.519501258320905), `5_2020` = c(-0.212694767652598, -0.745624343306066,
-0.745624343306066, -0.0613427681670131, -0.0558243683675047,
1.11383645870223), `6_2019` = c(1.42396566577408, 0.271423699181106,
-0.750147589389944, 2.9363922780621, 1.9850271509777, -0.30388223701417
), `6_2020` = c(1.79090164563637, -0.829110583156508, -0.829110583156508,
-0.829110583156508, 0.897799881648984, 0.586619586854488),
`7_2019` = c(0.184366159736715, -0.811535062585869, -0.811535062585869,
-0.811535062585869, -0.811535062585869, -0.811535062585869
), `7_2020` = c(0.0324441329441847, -0.451737568882596, -0.451737568882596,
0.947850162960442, -0.451737568882596, 0.111618499280639),
`8_2019` = c(0.545811057837518, -0.708105180577219, -0.708105180577219,
-0.708105180577219, 1.45426057750534, 0.300998839861308),
`8_2020` = c(0.441244935529506, -0.738475764850768, -0.738475764850768,
0.938233656115238, 6.42564630654944, 0.199683077832593),
`9_2019` = c(0.27604491200326, -0.64587760461491, -0.64587760461491,
2.84547711109649, -0.0693236148644031, -0.64587760461491),
`9_2020` = c(-0.169700283085442, 0.00608884199341344, 9.23594311455478,
-0.530530592457829, -0.530530592457829, 0.958261131172142
), Entity = c("TRUEBLUE INC", "TRIUMPH BANCORP INC", "GENERAC HOLDINGS INC",
"LABORATORY CP OF AMER HLDGS", "EW SCRIPPS -CL A", "NASDAQ INC"
), Ticker.Symbol = c("TBI", "TBK", "GNRC", "LH", "SSP", "NDAQ"
), Ra = c(0.00752445581408545, 0.650491365399341, 1.64312252649634,
0.589477428529553, 0.365794466353345, 0.559536316393495)), row.names = c(NA,
-6L), class = c("tbl_df", "tbl", "data.frame"))
CodePudding user response:
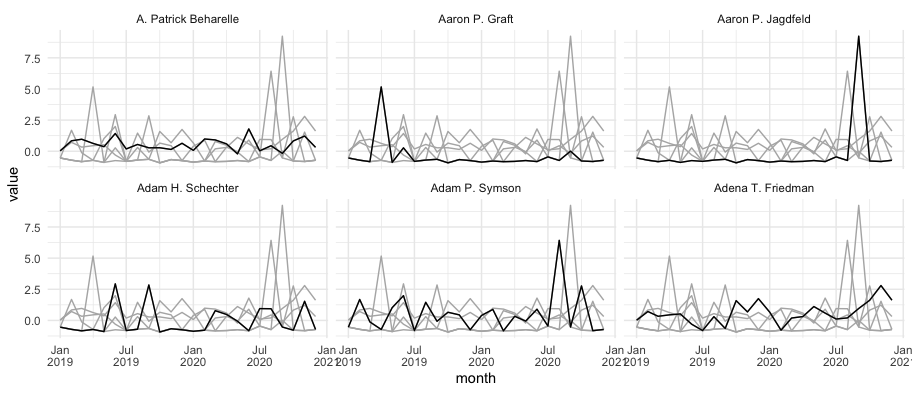
I think the two things that'd help would be to reshape your data into longer form, so each monthly observation gets a row, and to recharacterize the month labels into dates so that they can be plotted automatically in ggplot2.
It will be hard to distinguish dozens and dozens of separate time series, so you might want to pick certain outliers to highlight, or else show summary stats for the whole group. The "small multiples" approach here works for six individuals but would get unwieldy for dozens/hundreds.
Note that here I chose to add a layer with all the series in gray to give some background context, but you could skip that if it doesn't help for the point you're trying to make.
library(tidyverse)
df %>%
pivot_longer(-c(Full.Name, Entity:Ra)) %>%
mutate(month = lubridate::dmy(paste(1,name))) %>%
ggplot(aes(month, value, group = Ticker.Symbol))
geom_line(data = . %>% select(-Full.Name), color = "gray70")
geom_line()
scale_x_date(date_labels = "%b\n%Y")
facet_wrap(~Full.Name)
theme_minimal()
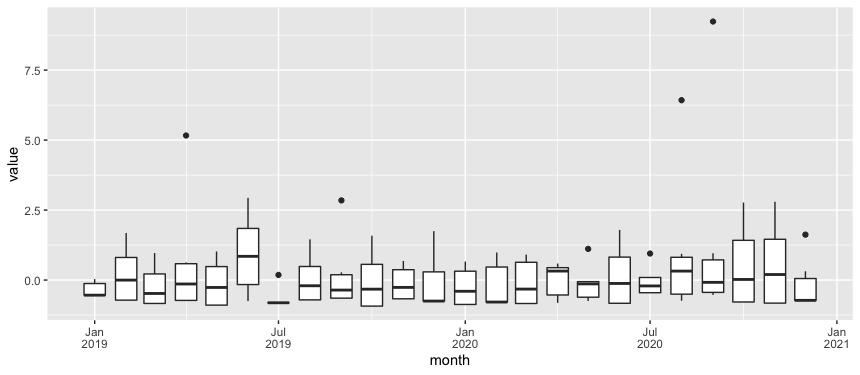
Or to see the "distribution of several months," you might use a boxplot to summarize the whole cohort:
df %>%
pivot_longer(-c(Full.Name, Entity:Ra)) %>%
mutate(month = lubridate::dmy(paste(1,name))) %>%
ggplot(aes(month, value, group = month))
geom_boxplot()
scale_x_date(date_labels = "%b\n%Y")