I have this fake data set with a column named location.
data.1 <-read.csv(text = "
location
01-Q2-Locate of este (TT)
02-Q2-Green River (OG)
01-Q1-Agabe (PS)
")
I need to partition the location column into three columns named code, name, and region.
This is my intended outcome:
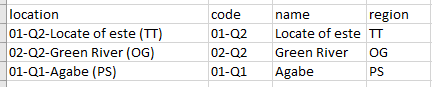
This is the code I am using:
library(dplyr)
library(tidyr)
data.1.new <- data.1 %>%
tidyr::separate(location, c("code", "name", "region"), extra = "merge", remove = FALSE)
The outcome I am getting is this:
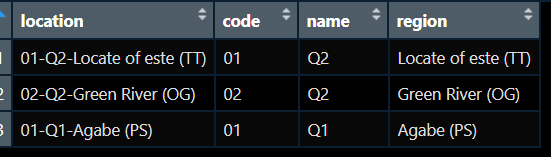
I couldn't find a way to separate to solve this.
CodePudding user response:
data.1 %>%
extract(location, c('code', 'name', 'region'), '(.*)-([^(] ) \\((.*)\\)')
code name region
1 01-Q2 Locate of este TT
2 02-Q2 Green River OG
3 01-Q1 Agabe PS
CodePudding user response:
Another possible solution:
library(tidyverse)
data.1 %>%
mutate(code = str_extract(location, "^\\d -\\D\\d "),
name = str_extract(location, "(?<=-)\\D (?=\\s\\()"),
zegion = str_extract(location, "(?<=\\().*(?=\\))"))
#> location code name zegion
#> 1 01-Q2-Locate of este (TT) 01-Q2 Locate of este TT
#> 2 02-Q2-Green River (OG) 02-Q2 Green River OG
#> 3 01-Q1-Agabe (PS) 01-Q1 Agabe PS