My engineering team is gearing up for a bidding on a public project, where the specifications document is huge (~500 pages). I would like to break it down clause by clause in a spreadsheet and then assign the teams the relevant "portion". I checked, but PDF document is the only way these specs are provided.
The idea is to record it such that we can compare it with specifications of previous projects that are recorded in similar manner. I am still a trainee, so am not aware how this process works around different companies, but here in my team, the last project was documented manually in a similar manner.
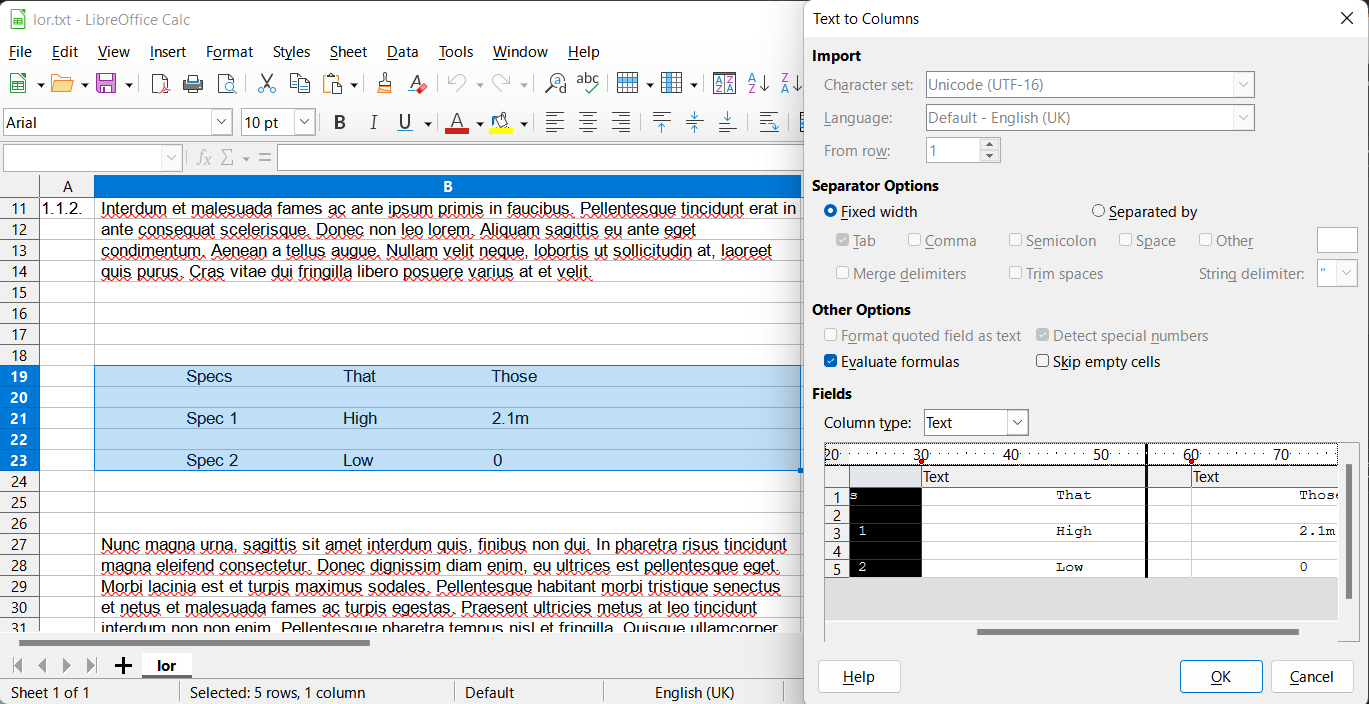
The pages are arranged in indexed paragraphs (as 1, 1.1, 1.1.1 etc) with some tables and figures thrown around.
I hope to get a table like this:
| Clause No. | Clause Para |
|---|---|
| 1.1. | Lorem Ipsum |
| 1.2. | Lorem Ipsum |
I asked around on PM Stackexchange if someone had some idea regarding any software suite, but I don't think there are many.
So I turned to R hoping that I could solve this maybe by parsing it using pdftools and a regex, and generally, while checking the code, I can get it to run on regex101.com to some extent (randomly selects few paragraphs, but fails when encounters a table) but somehow it does not return the same response when used with R.
I have no commitment to use R, but it is just that it was easilty available on my work laptop. Willing to try python or any other toolkit as well.
So far, I have been stuck on getting to make R get a single paragraph.
library(pdftools)
library(dplyr)
library(stringr)
library(purrr)
setwd("The work Dir/")
specDoc <- pdf_text("Spec Doc.pdf") %>% strsplit(split = "\n")
specDocChar <- as.character(specDoc)
get_clause <- str_trim(str_extract(specDocChar, "(?:^\n*(?:\\d\\.(?:\\d\\.)*) )(. ?)$"))
get_clause
I tried the lookbehind also, but it seems to not work with flexible starting string lengths.
At this point I wish to know two things mainly.
- What am I doing incorrectly that I end up having a blank output
- Is there a more efficient way to tackle this particular problem, because after the paragraphs, I am not sure how to manage the tables within the paragraph, and para alone takes a little too much time.

Google will simply offer the text without the css (unless you modify that html direct in an HTML scraper)

You have the source file (the one google downloaded).
So the one app you should already have is the best to extract the text.
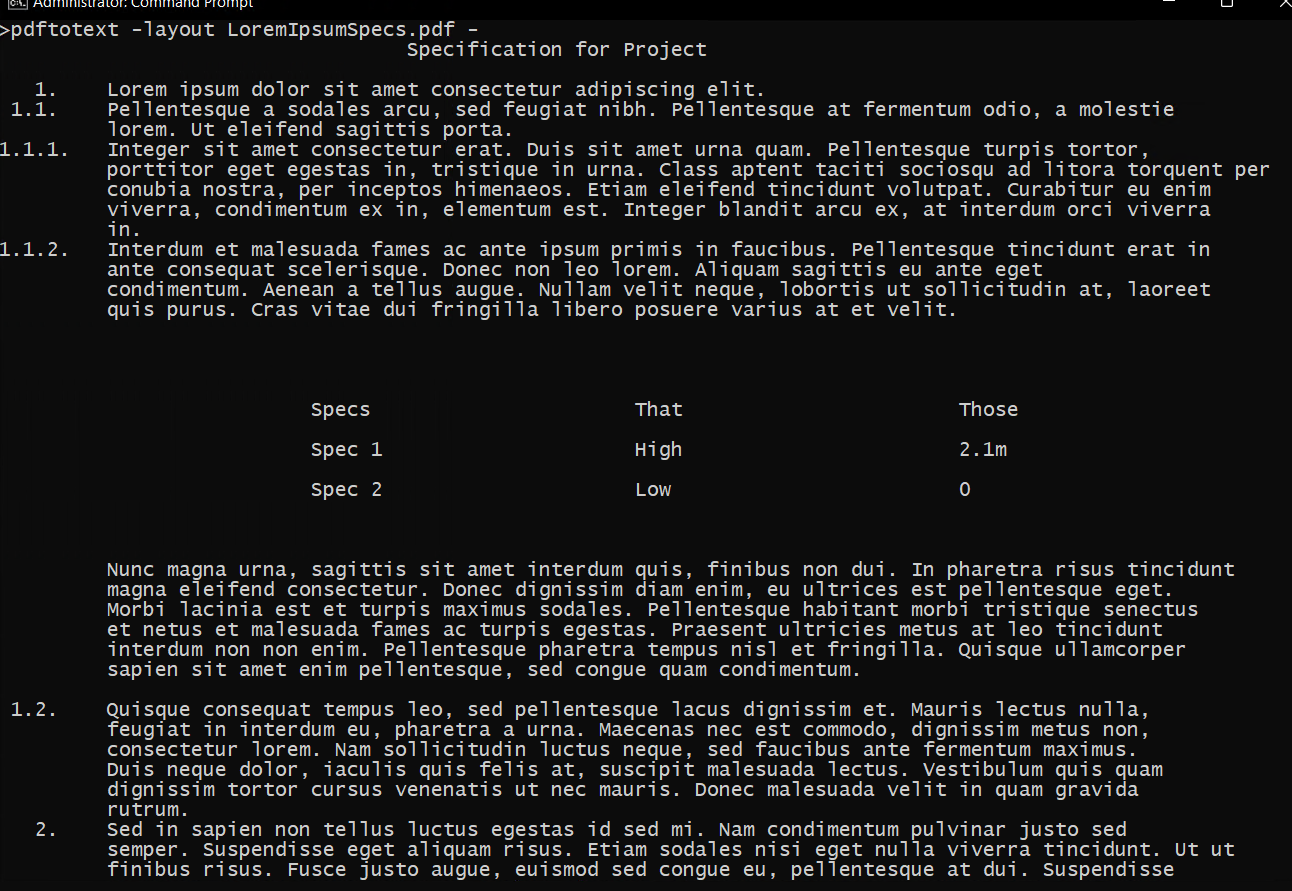
Clearly there are limitations such as no graphics or divisions like in the HTML. However if you just need to send the text to a bid collaborator for comment/action by refering to pdf named destinations (bookmarks) it is fast dirty and simple, more time to do your own bidding. Simpler may be to export eXcelX paragraphs from a cheap PDF editor like Xchange. or use adobe to convert to docx
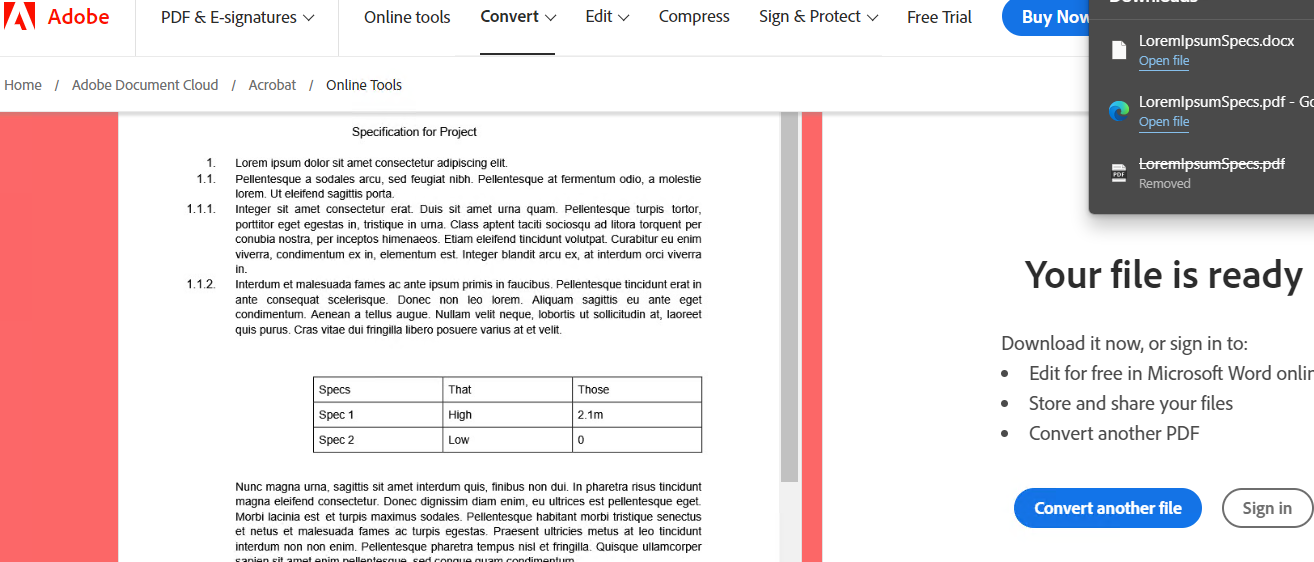
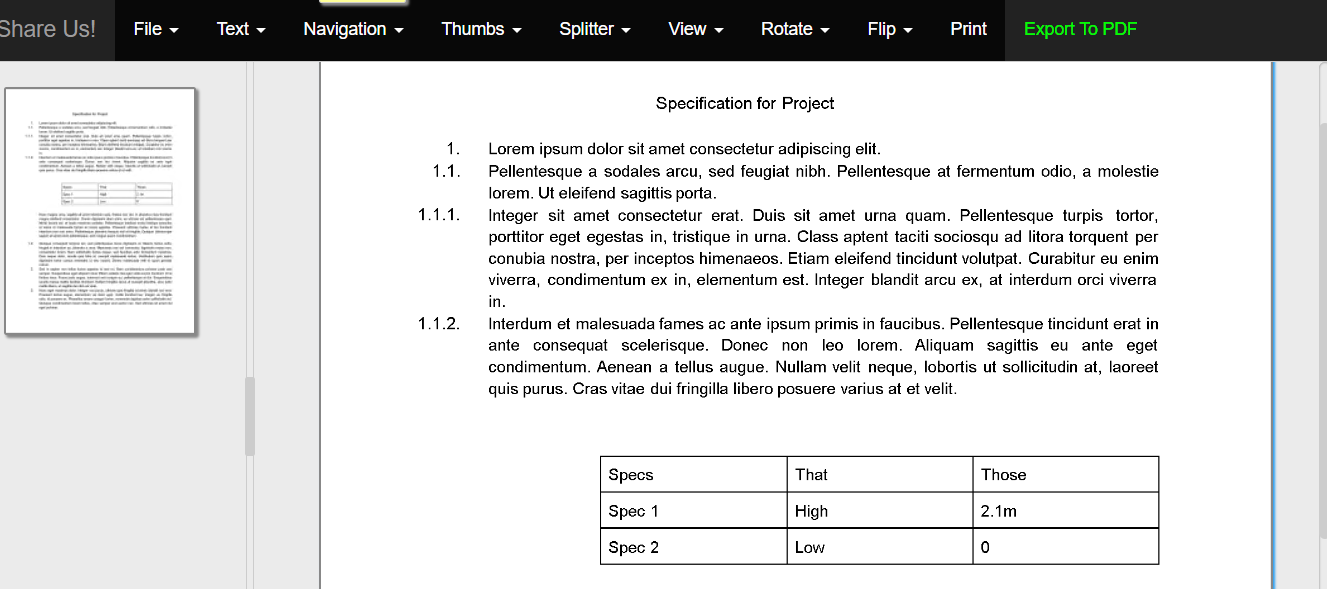
If you have your plain text you can paste or open in Word to apply styling, if needed.
However if there are tables to be redefined you can open the plain text in Office to draw the tables, here I set the first division on import between the numbers and body text and am redefining the table sub division.