Let's say I have 3 classes: 0, 1, 2
One-hot-encoding an array of labels can be done via pandas as follows:
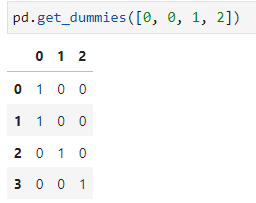
What I'm interested in, is how to get an encoding that can handle an intermediate class, e.g. class in the middle between 2 classes.
For example:
- for class
0.4, resulting encoding should be[0.4, 0.6, 0] - for class
1.8, resulting encoding should be[0, 0.2, 0.8]
Does anybody know such an encoder?
Thanks for your answer!
CodePudding user response:
You can write a function for your strange encoding like the below:
import numpy as np
import math
def strange_encode(num, cnt_lbl):
encode_arr = np.zeros(cnt_lbl)
lbl = math.floor(num)
if lbl != num:
num -= lbl
if num >= 0.5:
encode_arr[lbl:lbl 2] = [1-num, num]
else:
encode_arr[lbl:lbl 2] = [num, 1-num]
else:
encode_arr[lbl] = 1
return encode_arr
Output:
>>> encode(0.0, cnt_lbl=3)
array([1., 0., 0.])
>>> encode(2.0, cnt_lbl=3)
array([0., 0., 1.])
>>> encode(0.4, cnt_lbl=3)
array([0.4, 0.6, 0. ])
>>> encode(1.8, cnt_lbl=3)
array([0. , 0.2, 0.8])
# You can change the count of classes
>>> encode(2.5, cnt_lbl=4)
array([0. , 0. , 0.5, 0.5])
>>> encode(1.6, cnt_lbl=4)
array([0. , 0.4, 0.6, 0. ])
>>> encode(2, cnt_lbl=4)
array([0., 0., 1., 0.])
We can write a function for generating a dataframe for encoding like below:
import pandas as pd
def generate_df_encoding(arr_nums, num_classes):
arr = np.zeros((len(arr_nums), num_classes))
for idx, num in enumerate(arr_nums):
arr[idx] = strange_encode(num, cnt_lbl=num_classes)
return pd.DataFrame(arr)
Output:
>>> generate_df_encoding([0,0,1,2,0.4,1.8], num_classes=3)
0 1 2
0 1.0 0.0 0.0
1 1.0 0.0 0.0
2 0.0 1.0 0.0
3 0.0 0.0 1.0
4 0.4 0.6 0.0
5 0.0 0.2 0.8
CodePudding user response:
I'm not sure if this helps.
When you have categorial variables (classes), without order, that need to be encoded, you can use sklearn.preprocessing.LabelEncoder(). If there's an order, try using sklearn.preprocessing.OrdinalEncoder().
When you have numeric variables, the preprocessing steps I would use would be one of the many preprocessing tools you can find at https://scikit-learn.org/stable/modules/classes.html#module-sklearn.preprocessing ; a couple widely used are MinMaxScaler(), RobustScaler(), StandardScaler(), but it's best you read the API Reference guide to better understand when to use one or the other.