I am trying to mask a dataset I have based on two parameters
That I mask any station has a repeat value more than once per hour a) I want the count to reset once the clock hits a new hour
That I mask the data whenever the previous datapoint is lower than the current datapoint if it's within the hour and the station names are the same.
The mask I applied to it is this
mask = (df['station'] == df['station'].shift(1))
& (df['precip'] >= df['precip'].shift(1))
& (abs(df['valid'] - df['valid'].shift(1)) < pd.Timedelta('1 hour'))
df.loc[mask, 'to_remove'] = True
However it is not working properly giving me a df that looks like this
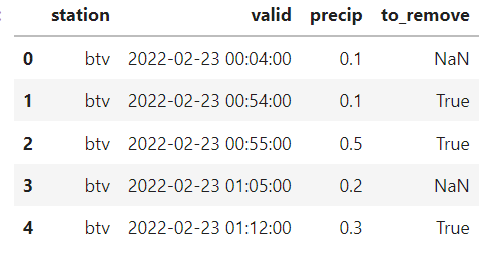
I want a dataframe that looks like this
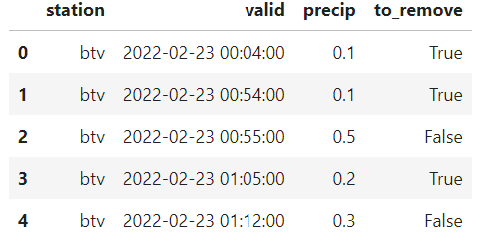
CodePudding user response:
Basically you want to mask two things, the first being a duplicate value per station & hour. This can be found by grouping by station and the hour of valid, plus the precip column. On this group by you can count the number of occurances and check if it is more than one:
df.groupby(
[df.station, df['valid'].apply(lambda x: x.hour), df.precip] #groupby the columns
).transform('count') > 1 #count the values and check if more than 1
The second one is not clear to me whether you want to reset once the clock hits a new hour (as mentioned in the first part of the mask). If this is also the case, you need to group by station and hour, and check values using shift (as you tried):
df.groupby(
[df.station, df['valid'].apply(lambda x: x.hour)] #group by station and hour
).precip.apply(lambda x: x < x.shift(1)) #value lower than previous
If this is not the case, as suggested by your expected output, you only group by station:
df.groupby(df.station).precip.apply(
lambda x: ( x < x.shift(1) ) & #value is less than previous
( abs(df['valid'] - df['valid'].shift(1) ) < pd.Timedelta('1 hour') ) #within hour
)
Combining these two masks will let you drop the right rows:
df['sameValueWithinHour'] = df.groupby([df.station, df['valid'].apply(lambda x: x.hour), df.precip]).transform('count')>1
df['previousValuelowerWithinHour'] = df.groupby(df.station).precip.transform(lambda x: (x<x.shift(1)) & (abs(df['valid'] - df['valid'].shift(1)) < pd.Timedelta('1 hour')))
df['to_remove'] = df.sameValueWithinHour | df.previousValuelowerWithinHour
df.loc[~df.to_remove, ['station', 'valid', 'precip']]
station valid precip
2 btv 2022-02-23 00:55:00 0.5
4 btv 2022-02-23 01:12:00 0.3