I am looking to total sections of a total column using the groupby function. When I use the groupby function 'code' it works however I would like to be able to filter it down to one nominal code by placing it in a variable and printing it.
subheading_one = df.groupby(['Code'])['Total'].sum()
subheading_two = df.groupby(['Code'])['Total'].sum()
subheading_three = df.groupby(['Code'])['Total'].sum()
print('Cost heading 1.1 £: ',subheading_one)
print('Cost heading 1.2 £: 'subheading_two)
print('Cost heading 1.3 £: 'subheading_three)
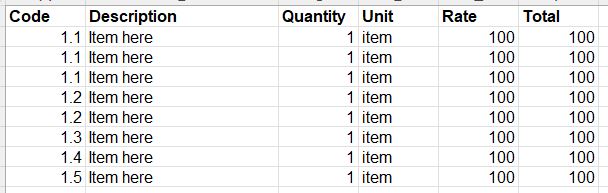
I have attached a snippet of the data frame. As you can see I would like to be able to total only '1.1' items and place that total into a variable (should equal 300). Can anybody help?
CodePudding user response:
You should be able to perform the .groupby operation once, and then use .loc to select the specific total you want:
totals = df.groupby(['Code'])['Total'].sum()
print('Cost heading 1.1 £: ', totals.loc['1.1'])
print('Cost heading 1.2 £: ', totals.loc['1.2'])
edit: If your code column are floats (not strings), you can do:
totals = df.groupby(['Code'])['Total'].sum()
print('Cost heading 1.1 £: ', totals.loc[1.1])
print('Cost heading 1.2 £: ', totals.loc[1.2])
CodePudding user response:
You can use the get_group like this
subheading_one = df.groupby(['Code'])['Total'].get_group('1.1').sum()
I am assuming your Code feature has string values.
CodePudding user response:
code = {'Code': [1.1, 1.1, 1.1, 1.2, 1.2, 1.3, 1.4, 1.5]}
df = pd.DataFrame(code)
df['Description'] = 'Item here'
df['Quantity'] = 1
df['Unit'] = 'Item'
df['Rate'] = 100
df['Total'] = 100
mask = df['Code'] == 1.1
subheading_one = df.loc[mask, 'Total'].sum()
mask = df['Code'] == 1.2
subheading_two = df.loc[mask, 'Total'].sum()
mask = df['Code'] == 1.3
subheading_three = df.loc[mask, 'Total'].sum()
print(f'Cost heading 1.1 £: {subheading_one}')
print(f'Cost heading 1.2 £: {subheading_two}')
print(f'Cost heading 1.3 £: {subheading_three}')