I have a fairly simple CSV that looks like this:
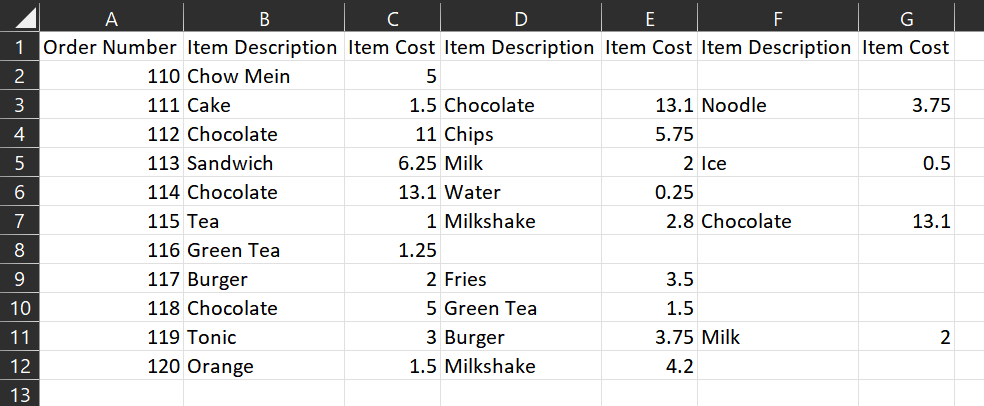
When I use pandas to read the CSV, columns that have the same name automatically gets renamed with a ".n" notation, as follows:
>>> import pandas as pd
>>> food = pd.read_csv("food.csv")
>>> food
Order Number Item Description Item Cost Item Description.1 Item Cost.1 Item Description.2 Item Cost.2
0 110 Chow Mein 5.00 NaN NaN NaN NaN
1 111 Cake 1.50 Chocolate 13.10 Noodle 3.75
2 112 Chocolate 11.00 Chips 5.75 NaN NaN
3 113 Sandwich 6.25 Milk 2.00 Ice 0.50
4 114 Chocolate 13.10 Water 0.25 NaN NaN
5 115 Tea 1.00 Milkshake 2.80 Chocolate 13.10
6 116 Green Tea 1.25 NaN NaN NaN NaN
7 117 Burger 2.00 Fries 3.50 NaN NaN
8 118 Chocolate 5.00 Green Tea 1.50 NaN NaN
9 119 Tonic 3.00 Burger 3.75 Milk 2.00
10 120 Orange 1.50 Milkshake 4.20 NaN NaN
>>>
food.csv:
Order Number,Item Description,Item Cost,Item Description,Item Cost,Item Description,Item Cost
110,Chow Mein,5,,,,
111,Cake,1.5,Chocolate,13.1,Noodle,3.75
112,Chocolate,11,Chips,5.75,,
113,Sandwich,6.25,Milk,2,Ice,0.5
114,Chocolate,13.1,Water,0.25,,
115,Tea,1,Milkshake,2.8,Chocolate,13.1
116,Green Tea,1.25,,,,
117,Burger,2,Fries,3.5,,
118,Chocolate,5,Green Tea,1.5,,
119,Tonic,3,Burger,3.75,Milk,2
120,Orange,1.5,Milkshake,4.2,,
As such, queries that rely on the column names will only work if they match the first column (e.g.):
>>> print(food[(food['Item Description'] == "Chocolate") & (food['Item Cost'] == 13.10)]['Order Number'].to_string(index=False))
114
While I can technically lengthen the masks to include the .1 and .2 columns, this seems relatively inefficient, especially when the number of duplicated columns is large (in this example there are only 3 sets of duplicated columns, but in other datasets, I have a large number which would not work well if I just construct a mask for each column.)
I am not sure if I am approaching this the right way or if I am missing something simple (like in loading the CSV) or if there are some groupbys I can do that can answer the same question (i.e. Find the order numbers when the order contains an item that has chocolate listed that costs $13.10).
Would the problem be different if it's something like: average all the costs of chocolates paid for all the orders?
Thanks in advance.
CodePudding user response:
It's often easier to operate on a table in "long" form instead of "wide" form that you currently have.
There's example code below to convert from an example wide_df:
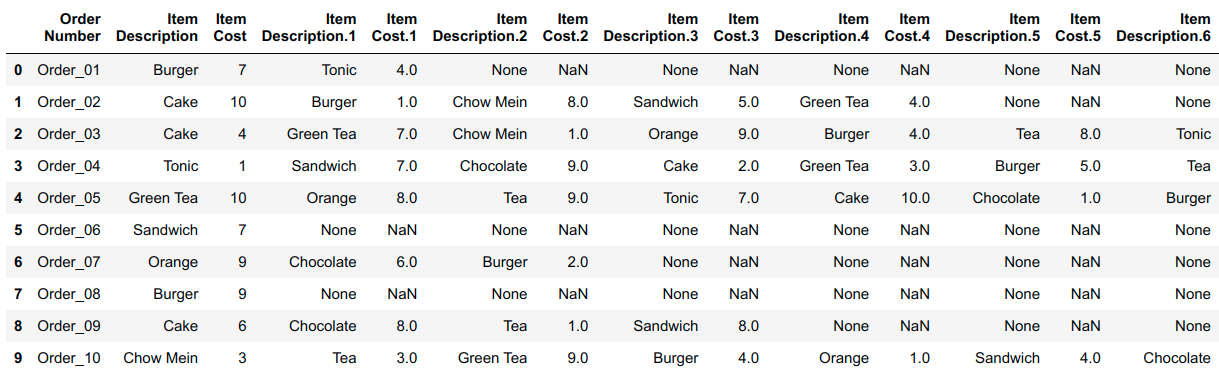
To a long df version:
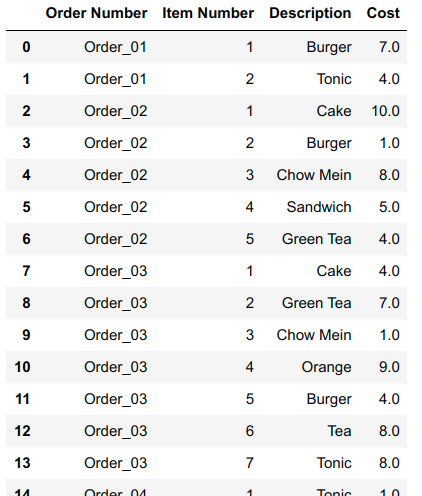
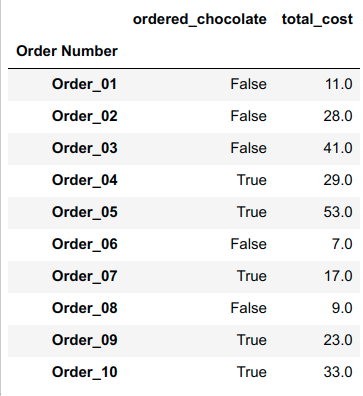
In the long_df version each row is a unique Order/Item and now we don't have to store any null values. Pandas also makes it easy to perform grouping operations on tables in long form. Here's what the agg table looks like from the code below
You can also easily make your query of finding orders where a chocolate cost $13.10 by long_df[long_df['Description'].eq('Chocolate') & long_df['Cost'].eq(13.10)]['Order Number'].unique()
import pandas as pd
import numpy as np
df = pd.DataFrame({
'Order Number': ['Order_01', 'Order_02', 'Order_03', 'Order_04', 'Order_05', 'Order_06', 'Order_07', 'Order_08', 'Order_09', 'Order_10'],
'Item Description': ['Burger', 'Cake', 'Cake', 'Tonic', 'Green Tea', 'Sandwich', 'Orange', 'Burger', 'Cake', 'Chow Mein'],
'Item Cost': [7, 10, 4, 1, 10, 7, 9, 9, 6, 3],
'Item Description.1': ['Tonic', 'Burger', 'Green Tea', 'Sandwich', 'Orange', None, 'Chocolate', None, 'Chocolate', 'Tea'],
'Item Cost.1': [4.0, 1.0, 7.0, 7.0, 8.0, np.nan, 6.0, np.nan, 8.0, 3.0],
'Item Description.2': [None, 'Chow Mein', 'Chow Mein', 'Chocolate', 'Tea', None, 'Burger', None, 'Tea', 'Green Tea'],
'Item Cost.2': [np.nan, 8.0, 1.0, 9.0, 9.0, np.nan, 2.0, np.nan, 1.0, 9.0],
'Item Description.3': [None, 'Sandwich', 'Orange', 'Cake', 'Tonic', None, None, None, 'Sandwich', 'Burger'],
'Item Cost.3': [np.nan, 5.0, 9.0, 2.0, 7.0, np.nan, np.nan, np.nan, 8.0, 4.0],
'Item Description.4': [None, 'Green Tea', 'Burger', 'Green Tea', 'Cake', None, None, None, None, 'Orange'],
'Item Cost.4': [np.nan, 4.0, 4.0, 3.0, 10.0, np.nan, np.nan, np.nan, np.nan, 1.0],
'Item Description.5': [None, None, 'Tea', 'Burger', 'Chocolate', None, None, None, None, 'Sandwich'],
'Item Cost.5': [np.nan, np.nan, 8.0, 5.0, 1.0, np.nan, np.nan, np.nan, np.nan, 4.0],
'Item Description.6': [None, None, 'Tonic', 'Tea', 'Burger', None, None, None, None, 'Chocolate'],
'Item Cost.6': [np.nan, np.nan, 8.0, 2.0, 8.0, np.nan, np.nan, np.nan, np.nan, 9.0],
})
# Convert table to long form
desc_cols = [c for c in df.columns if 'Desc' in c]
cost_cols = [c for c in df.columns if 'Cost' in c]
desc_df = df.melt(id_vars='Order Number', value_vars=desc_cols, value_name='Description')
cost_df = df.melt(id_vars='Order Number', value_vars=cost_cols, value_name='Cost')
long_df = pd.concat((desc_df[['Order Number','Description']], cost_df[['Cost']]), axis=1).dropna()
long_df.insert(1,'Item Number',long_df.groupby('Order Number').cumcount().add(1))
long_df = long_df.sort_values(['Order Number','Item Number'])
# Calculate group info
group_info = long_df.groupby('Order Number').agg(
ordered_chocolate = ('Description', lambda d: d.eq('Chocolate').any()),
total_cost = ('Cost','sum'),
)
CodePudding user response:
Here's a bit of a simpler approach with pandas' wide_to_long function (i will use the df provided by @mitoRibo in another answer)
documentation: https://pandas.pydata.org/docs/reference/api/pandas.wide_to_long.html
import pandas as pd
import numpy as np
df = pd.DataFrame({
'Order Number': ['Order_01', 'Order_02', 'Order_03', 'Order_04', 'Order_05', 'Order_06', 'Order_07', 'Order_08', 'Order_09', 'Order_10'],
'Item Description': ['Burger', 'Cake', 'Cake', 'Tonic', 'Green Tea', 'Sandwich', 'Orange', 'Burger', 'Cake', 'Chow Mein'],
'Item Cost': [7, 10, 4, 1, 10, 7, 9, 9, 6, 3],
'Item Description.1': ['Tonic', 'Burger', 'Green Tea', 'Sandwich', 'Orange', None, 'Chocolate', None, 'Chocolate', 'Tea'],
'Item Cost.1': [4.0, 1.0, 7.0, 7.0, 8.0, np.nan, 6.0, np.nan, 8.0, 3.0],
'Item Description.2': [None, 'Chow Mein', 'Chow Mein', 'Chocolate', 'Tea', None, 'Burger', None, 'Tea', 'Green Tea'],
'Item Cost.2': [np.nan, 8.0, 1.0, 9.0, 9.0, np.nan, 2.0, np.nan, 1.0, 9.0],
'Item Description.3': [None, 'Sandwich', 'Orange', 'Cake', 'Tonic', None, None, None, 'Sandwich', 'Burger'],
'Item Cost.3': [np.nan, 5.0, 9.0, 2.0, 7.0, np.nan, np.nan, np.nan, 8.0, 4.0],
'Item Description.4': [None, 'Green Tea', 'Burger', 'Green Tea', 'Cake', None, None, None, None, 'Orange'],
'Item Cost.4': [np.nan, 4.0, 4.0, 3.0, 10.0, np.nan, np.nan, np.nan, np.nan, 1.0],
'Item Description.5': [None, None, 'Tea', 'Burger', 'Chocolate', None, None, None, None, 'Sandwich'],
'Item Cost.5': [np.nan, np.nan, 8.0, 5.0, 1.0, np.nan, np.nan, np.nan, np.nan, 4.0],
'Item Description.6': [None, None, 'Tonic', 'Tea', 'Burger', None, None, None, None, 'Chocolate'],
'Item Cost.6': [np.nan, np.nan, 8.0, 2.0, 8.0, np.nan, np.nan, np.nan, np.nan, 9.0],
})
df.rename(columns={'Item Description': 'Item Description.0', 'Item Cost': 'Item Cost.0'}, inplace=True)
long = pd.wide_to_long(df, stubnames=['Item Description', 'Item Cost'], i="Order Number", j="num_after_col_name", sep='.')