I am working with the data set that contains columns with information about age and sex stored together (e.g Y_0_13_Males, Y_0_13_Females, Y_0_13_Unknown, etc.). Below you can see the dataset
structure(list(Y_O_13_Males = c(5, 0, 0, 0, 0), Y_O_13_Females = c(4,
0, 0, 0, 0), Y_O_13_Unknown = c(1, 0, 0, 0, 0), Y65_And_Over_Males = c(0,
0, 0, 0, 0), Y65_And_Over_Females = c(0, 0, 0, 0, 0), Y65_And_Over_Unknown = c(0,
0, 0, 0, 0), Unknown_And_Over_Males = c(0, 0, 0, 0, 0), Unknown_And_Over_Females = c(0,
0, 0, 0, 0), Unknown_And_Over_Unknown = c(0, 0, 0, 0, 0)), row.names = c(NA,
-5L), class = c("tbl_df", "tbl", "data.frame"))
Now I want to convert this data into format that is shown below :
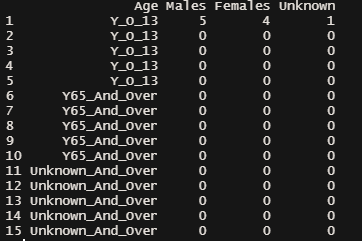
So can anybody help me how to solve this and convert data into format showed above ?
CodePudding user response:
The key to doing it is to set names_pattern in pivot_longer, so that each column can be "split" into two parts, with the later part containing the values.
After pivoting the data, we need to set factor for the Age column then arrange it so that it fits your desired order.
library(tidyr)
library(mutate)
df %>% pivot_longer(everything(), names_to = c("Age", ".value"),
names_pattern = "(.*)_(.*)") %>%
mutate(Age = factor(Age, levels = c("Y_O_13", "Y65_And_Over", "Unknown_And_Over"))) %>%
arrange(Age)
# A tibble: 15 × 4
Age Males Females Unknown
<fct> <dbl> <dbl> <dbl>
1 Y_O_13 5 4 1
2 Y_O_13 0 0 0
3 Y_O_13 0 0 0
4 Y_O_13 0 0 0
5 Y_O_13 0 0 0
6 Y65_And_Over 0 0 0
7 Y65_And_Over 0 0 0
8 Y65_And_Over 0 0 0
9 Y65_And_Over 0 0 0
10 Y65_And_Over 0 0 0
11 Unknown_And_Over 0 0 0
12 Unknown_And_Over 0 0 0
13 Unknown_And_Over 0 0 0
14 Unknown_And_Over 0 0 0
15 Unknown_And_Over 0 0 0