In the following data frame for those records where id and name are same I want to remove those rows where class is 0
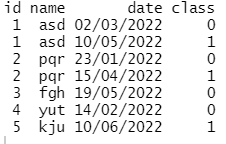
for e.g. 1st and 2nd record have same id and name. Similarly 3rd and 4th record.
The final data frame will be as below
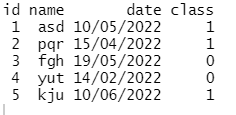
Please help how to do it in r. My actual dataset has thousands of such records
Here is the sample dataset
Data <- data.frame(id = c(1,1,2,2,3,4,5),name = c("asd","asd","pqr","pqr","fgh","yut","kju"),
date = c("02/03/2022","10/05/2022","23/01/2022","15/04/2022","19/05/2022","14/02/2022","10/06/2022"),
class = c(0,1,0,1,0,0,1))
CodePudding user response:
You may try,
library(dplyr)
Data %>%
group_by(id) %>%
filter(!(n() > 1 & class == 0))
id name date class
<dbl> <chr> <chr> <dbl>
1 1 asd 10/05/2022 1
2 2 pqr 15/04/2022 1
3 3 fgh 19/05/2022 0
4 4 yut 14/02/2022 0
5 5 kju 10/06/2022 1
CodePudding user response:
Or an data.table approach:
library(data.table)
setDT(Data)
unique(Data[order(id, -class)], by="name")
Output:
| id|name |date | class|
|--:|:----|:----------|-----:|
| 1|asd |10/05/2022 | 1|
| 2|pqr |15/04/2022 | 1|
| 3|fgh |19/05/2022 | 0|
| 4|yut |14/02/2022 | 0|
| 5|kju |10/06/2022 | 1|