I have been trying this for way to long and can't seem to figure out a concise way to extract the browser from the string. It is a column in a df so it needs to iterate over all the rows
The column looks like this
0 [{'name': 'Chrome', 'version': '36.0.1985.143'}]
1 [{'name': 'Chrome', 'version': '34.0.1847.137'}]
2 [{'name': 'Chrome', 'version': '29.0.1547.76'}]
3 [{'name': 'Chrome', 'version': '33.0.1750.154'}]
4 [{'name': 'Chrome', 'version': '36.0.1985.143'}]
The column is called browser.
I have tried the following.
df_agent_info['browser'].str.split("\[\{\'[a\-z]\'")
and other worse examples. I appreciate the help.
CodePudding user response:
import re
pattern = r"(?<='name': ')[\w ] "
def match(x):
if re.findall(pattern, x):
return re.findall(pattern, x)[0]
df['browser'].apply(match)
(?<='name': ') is a positive lookahead: it looks for matches that follow in this case 'name': '
CodePudding user response:
Given:
browser
0 [{'name': 'Chrome', 'version': '36.0.1985.143'}]
1 [{'name': 'Chrome', 'version': '34.0.1847.137'}]
2 [{'name': 'Chrome', 'version': '29.0.1547.76'}]
3 [{'name': 'Chrome', 'version': '33.0.1750.154'}]
4 [{'name': 'Chrome', 'version': '36.0.1985.143'}]
Let's evaluate them as python:
df.browser = df.browser.apply(eval)
Now we can extract it easily:
df.browser = df.browser.str[0].str.get('name')
print(df)
Output:
browser
0 Chrome
1 Chrome
2 Chrome
3 Chrome
4 Chrome
CodePudding user response:
First convert the strings to lists containing a dict using the built-in ast.literal_eval (it is safer than using eval), and then get the 'name' value of each dictionary using list_dict[0]['name']. Apply this logic to each string value of the browser column using Series.apply.
Putting all together:
import pandas as pd
import ast
df_agent_info = pd.DataFrame({
'browser': ["[{'name': 'Chrome', 'version': '36.0.1985.143'}]",
"[{'name': 'Chrome', 'version': '34.0.1847.137'}]",
"[{'name': 'Chrome', 'version': '29.0.1547.76'}]",
"[{'name': 'Chrome', 'version': '33.0.1750.154'}]",
"[{'name': 'Chrome', 'version': '36.0.1985.143'}]"]
})
df_agent_info['browser'] = df_agent_info['browser'].apply(lambda s: ast.literal_eval(s)[0]['name'])
Output:
>>> df_agent_info['browser']
0 Chrome
1 Chrome
2 Chrome
3 Chrome
4 Chrome
Name: browser, dtype: object
CodePudding user response:
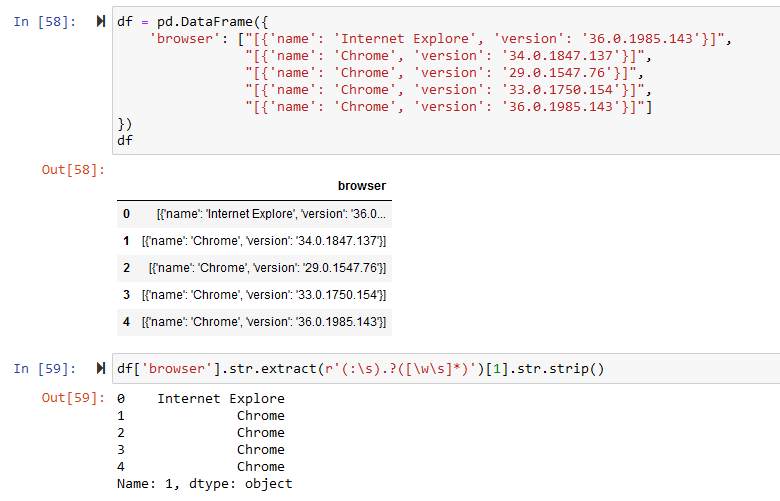
here is another way to do it, One liner
using regex groups to match for content b/w the astrophes, by using regex groups
df['browser'].str.extract(r'(:\s).?([\w\s]*)')[1].str.strip()
0 Internet Explore
1 Chrome
2 Chrome
3 Chrome
4 Chrome
Name: 1, dtype: object
df = pd.DataFrame({
'browser': ["[{'name': 'Internet Explore', 'version': '36.0.1985.143'}]",
"[{'name': 'Chrome', 'version': '34.0.1847.137'}]",
"[{'name': 'Chrome', 'version': '29.0.1547.76'}]",
"[{'name': 'Chrome', 'version': '33.0.1750.154'}]",
"[{'name': 'Chrome', 'version': '36.0.1985.143'}]"]
})