I have an Excel workbook with a bunch of sheets that I want to pull the contents of cell B4 and put all of those cells into a list, not a dictionary. I'm also pulling information from other parts of each sheet but I don't think I can do both at the same time so my code looks like this:
sheets = pd.read_excel(f, sheet_name=None, index_col=None, usecols="D:G", skiprows=14, nrows=8)
cells = pd.read_excel(f, sheet_name=None, index_col=None, header=None, usecols="B", skiprows=5, nrows=0)
I then tried to convert cells into a dataframe (because each of the items in sheets is a dataframe):
cells2 = pd.DataFrame.from_dict(cells)
and I get this error:
ValueError: If using all scalar values, you must pass an index
CodePudding user response:
I still didn't get the whole picture of your data.
But here's an approach.
The example of excel content I used(only one sheet).
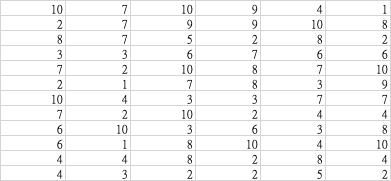
I didn't use argument: sheet_name=None(if it only contains one sheet)
cells = pd.read_excel('example.xlsx',header=None, index_col=None, usecols="B", skiprows=5)
cells = cells.rename(columns={1:"B"}) # rename column for readability
print(cells)
Output
B
0 1
1 4
2 2
3 10
4 1
5 4
6 3
It looks like you wanna put a series into list,
therefore we select the series, and its column name is 'B'
cells['B'].values.tolist()
Output
[1, 4, 2, 10, 1, 4, 3]
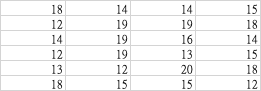
With multi-sheets
And we try to put every B4 of each sheet into a list.
sheet1
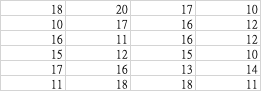
sheet2
sheet3
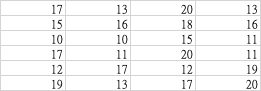
sheets = pd.read_excel('example_3sheets.xlsx',sheet_name=None,header=None, index_col=None, usecols="B", skiprows=3)
print(sheets)
Output
{'sheet1': 1
0 19
1 12
2 15, 'sheet2': 1
0 11
1 17
2 13, 'sheet3': 1
0 20
1 15
2 15}
That is actually three key-value pairs,
like three boxes with name on it,
and what is in the box?
a DataFrame!
That's why you got the error syntax, while the dict's values are not list-like content.
You can select the first dataframe by:
sheets['sheet1']
Output
1
0 19
1 12
2 15
And check the type:
type(sheets['sheet1'])
Output
pandas.core.frame.DataFrame
Iterate for every dataframe
for key in sheets:
print(sheets[key])
Output
1
0 19
1 12
2 15
1
0 11
1 17
2 13
1
0 20
1 15
2 15
Finally
According to the skiprows=3, B4 is in every dataframe's first element, we can select by iloc
b4_in_every_sheet = []
for key in sheets:
b4_in_every_sheet.append(sheets[key].iloc[0,0])
print(b4_in_every_sheet)
Output
[19, 11, 20]
another way with list comprehension
b4_in_every_sheet_2 = [sheets[key].iloc[0,0] for key in sheets]
print(b4_in_every_sheet_2)
Output
[19, 11, 20]
Hope it helps.