I really stuck in this problem and dont have any idea how to solve that. I have two data frame, one is for the humidity and its data are reported every 15 minutes. I have three different sensors for reporting. So, the table includes the id, the date, and hour of the reporting. Here is:
df_h = pd.DataFrame({'id_h': {0: 1, 1: 1, 2: 2, 3: 2, 4: 3, 5: 3}, 'date': {0: '2021-01-01', 1: '2021-01-01', 2: '2021-01-01', 3: '2021-01-01', 4: '2021-01-01', 5: '2021-01-01'}, 'time_hour': {0: '6:00:00', 1: '6:15:00', 2: '6:00:00', 3: '6:15:00', 4: '6:00:00', 5: '6:15:00'}, 'VALUE': {0: 10, 1: 12, 2: 20, 3: 22, 4: 30, 5: 32}})
id_h date time_hour VALUE
0 1 2021-01-01 6:00:00 10
1 1 2021-01-01 6:15:00 12
2 2 2021-01-01 6:00:00 20
3 2 2021-01-01 6:15:00 22
4 3 2021-01-01 6:00:00 30
5 3 2021-01-01 6:15:00 32
with the following code, I can stick its data together and for each id, in each day, I have the humidity.
humidity_sticked = df_h.pivot(index=["id_h", "date"], columns="time_hour", values="VALUE")
humidity_sticked.columns = [f"value_{i 1}" for i in range(humidity_sticked.shape[1])]
humidity_sticked =humidity_sticked.reset_index()
As we can see, we have a table with three rows and two columns.
Also, I have another table which shows the temperature. But, the id for the weather center is different. For example, for id_h (id of humidity) = 1, 2 we only have the id_t (id of temperature) = 5. So, we have exact same table for the temperature, but since the ids are different, I can not create the same stick table as humidity. Here is the table for the temperature:
df_t = pd.DataFrame({'id_t': {0: 5, 1: 5, 2: 5, 3: 5, 4: 7}, 'date': {0: '2021-01-01', 1: '2021-01-01', 2: '2021-01-01', 3: '2021-01-01', 4: '2021-01-01'}, 'time_hour': {0: '6:00:00', 1: '6:15:00', 2: '6:00:00', 3: '6:15:00', 4: '6:00:00'}, 'VALUE': {0: -1, 1: -8, 2: -2, 3: -9, 4: -3}})
id_t date time_hour VALUE
0 5 2021-01-01 6:00:00 -1
1 5 2021-01-01 6:15:00 -8
2 5 2021-01-01 6:00:00 -2
3 5 2021-01-01 6:15:00 -9
4 7 2021-01-01 6:00:00 -3
When I want to stick the values for id_t=5, I got an error. The desired output which I want is:
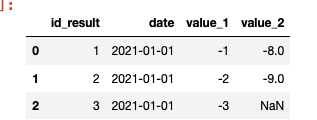
Explanation: for id_h=1,2 we have two 5. So, for the first two rows we consider as 1, the second two rows as id=2 and the last two rows are for id=3 which are for id_t=7.
Any help can save me!Thanks
CodePudding user response:
df_t['rank'] = df_t.id_t.rank(method='dense')
df_h['rank'] = df_h.id_h.rank(method='dense')
df = df_t.merge(df_h, on=['rank', 'date', 'time_hour'], suffixes=['_1', '_2'])
print(df)
Output:
id_t date time_hour VALUE_1 rank id_h VALUE_2
0 5 2021-01-01 6:00:00 -1 1.0 1 10
1 5 2021-01-01 6:00:00 -2 1.0 1 10
2 5 2021-01-01 6:15:00 -8 1.0 1 12
3 5 2021-01-01 6:15:00 -9 1.0 1 12
4 7 2021-01-01 6:00:00 -3 2.0 2 20
CodePudding user response:
You can use the pd.merge by index. This way is the shortcut to make your 'sticked dataframe'.
pd.merge(df_t, df_h, left_index=True, right_index=True, suffixes=['_t', '_h'])
Output:
id_t date_t time_hour_t VALUE_t id_h date_h time_hour_h \
0 5 2021-01-01 6:00:00 -1 1 2021-01-01 6:00:00
1 5 2021-01-01 6:15:00 -8 1 2021-01-01 6:15:00
2 5 2021-01-01 6:00:00 -2 2 2021-01-01 6:00:00
3 5 2021-01-01 6:15:00 -9 2 2021-01-01 6:15:00
4 7 2021-01-01 6:00:00 -3 3 2021-01-01 6:00:00
VALUE_h
0 10
1 12
2 20
3 22
4 30
The output above contains useless columns, so you can merge df_t and df_h[only you need to merge] like below:
pd.merge(df_t, df_h[['id_h','VALUE']], left_index=True, right_index=True, suffixes=['_t', '_h'])
Output:
id_t date time_hour VALUE_t id_h VALUE_h
0 5 2021-01-01 6:00:00 -1 1 10
1 5 2021-01-01 6:15:00 -8 1 12
2 5 2021-01-01 6:00:00 -2 2 20
3 5 2021-01-01 6:15:00 -9 2 22
4 7 2021-01-01 6:00:00 -3 3 30
This is the simplest way you want.