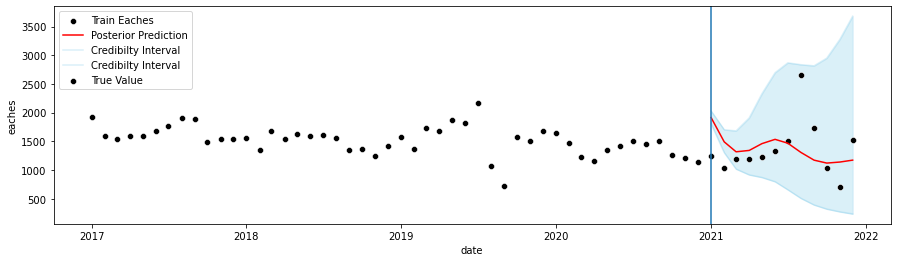
I have a training and testing time series dataset that I would like to combine togther, to show how well the forecast did predicting the testing dataset.
Here is the toy code to reproduce the data:
import pandas as pd
import seaborn as sns
train_date = ['2017-01-01T00:00:00.000000000', '2017-02-01T00:00:00.000000000',
'2017-03-01T00:00:00.000000000', '2017-04-01T00:00:00.000000000',
'2017-05-01T00:00:00.000000000', '2017-06-01T00:00:00.000000000',
'2017-07-01T00:00:00.000000000', '2017-08-01T00:00:00.000000000',
'2017-09-01T00:00:00.000000000', '2017-10-01T00:00:00.000000000',
'2017-11-01T00:00:00.000000000', '2017-12-01T00:00:00.000000000',
'2018-01-01T00:00:00.000000000', '2018-02-01T00:00:00.000000000',
'2018-03-01T00:00:00.000000000', '2018-04-01T00:00:00.000000000',
'2018-05-01T00:00:00.000000000', '2018-06-01T00:00:00.000000000',
'2018-07-01T00:00:00.000000000', '2018-08-01T00:00:00.000000000',
'2018-09-01T00:00:00.000000000', '2018-10-01T00:00:00.000000000',
'2018-11-01T00:00:00.000000000', '2018-12-01T00:00:00.000000000',
'2019-01-01T00:00:00.000000000', '2019-02-01T00:00:00.000000000',
'2019-03-01T00:00:00.000000000', '2019-04-01T00:00:00.000000000',
'2019-05-01T00:00:00.000000000', '2019-06-01T00:00:00.000000000',
'2019-07-01T00:00:00.000000000', '2019-08-01T00:00:00.000000000',
'2019-09-01T00:00:00.000000000', '2019-10-01T00:00:00.000000000',
'2019-11-01T00:00:00.000000000', '2019-12-01T00:00:00.000000000',
'2020-01-01T00:00:00.000000000', '2020-02-01T00:00:00.000000000',
'2020-03-01T00:00:00.000000000', '2020-04-01T00:00:00.000000000',
'2020-05-01T00:00:00.000000000', '2020-06-01T00:00:00.000000000',
'2020-07-01T00:00:00.000000000', '2020-08-01T00:00:00.000000000',
'2020-09-01T00:00:00.000000000', '2020-10-01T00:00:00.000000000',
'2020-11-01T00:00:00.000000000', '2020-12-01T00:00:00.000000000']
test_date = ['2021-01-01T00:00:00.000000000', '2021-02-01T00:00:00.000000000',
'2021-03-01T00:00:00.000000000', '2021-04-01T00:00:00.000000000',
'2021-05-01T00:00:00.000000000', '2021-06-01T00:00:00.000000000',
'2021-07-01T00:00:00.000000000', '2021-08-01T00:00:00.000000000',
'2021-09-01T00:00:00.000000000', '2021-10-01T00:00:00.000000000',
'2021-11-01T00:00:00.000000000', '2021-12-01T00:00:00.000000000']
train_eaches = [1915.0, 1597.0, 1533.0, 1601.0, 1585.0, 1675.0, 1760.0, 1910.0, 1886.0, 1496.0, 1545.0, 1538.0, 1565.0, 1350.0,1686.0, 1535.0, 1629.0, 1589.0, 1605.0, 1560.0, 1353.0,1366.0, 1246.0, 1423.0, 1579.0, 1368.0, 1727.0, 1687.0, 1872.0, 1824.0, 2161.0, 1065.0, 727.0, 1567.0, 1509.0, 1687.0, 1647.0,1476.0, 1231.0, 1165.0, 1341.0, 1425.0, 1502.0, 1450.0, 1497.0, 1259.0, 1207.0, 1132.0]
test_eaches = [1252.0, 1038.0, 1184.0, 1200.0, 1219.0, 1339.0, 1504.0, 2652.0, 1724.0, 1029.0,
711.0, 1530.0]
test_predictions = [1914.7225, 1490.4715, 1317.4765, 1341.263375, 1459.5875, 1534.2375, 1467.208875, 1306.2145, 1171.652625, 1120.641, 1138.912, 1171.914125]
test_credibility_down = [1805. , 1303. , 1017. , 915.975, 870.975, 797. ,
657. , 507. , 392. , 320. , 272. , 235. ]
test_credibility_up = [2029.025, 1702. , 1681.025, 1908. , 2329.05 , 2695.025,
2867.075, 2835. , 2815.075, 2949. , 3278.025, 3679. ]
train_df = pd.DataFrame.from_dict({'date':train_date, 'eaches':train_eaches})
test_df = pd.DataFrame.from_dict({'date':test_date, 'eaches':test_eaches, '2.5% Credibilty':test_credibility_down,
'97.5% Credibility':test_credibility_up})
Here are the two plots (train and test) and code that produces those plots:
fig = plt.figure(figsize=(15,4))
c=sns.scatterplot(x =train_df['date'], y = train_df['eaches'], label = 'Train Eaches',
color = 'black')
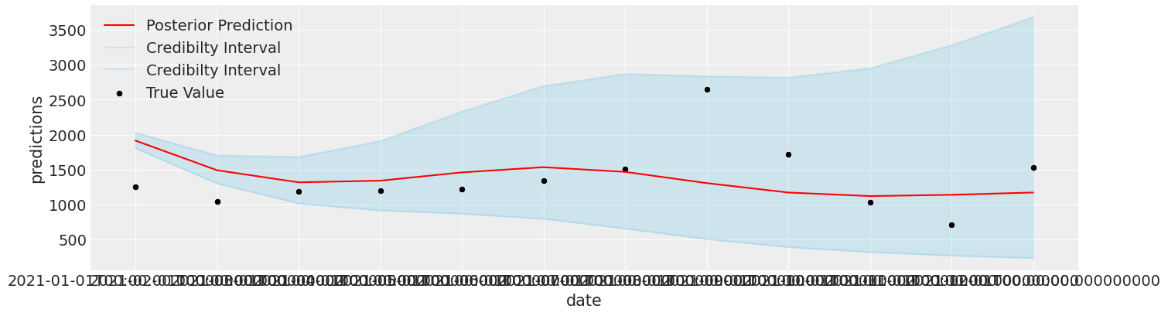
fig = plt.figure(figsize=(15,4))
a=sns.lineplot(x =test_df['date'], y = test_df['predictions'], label = 'Posterior Prediction', color = 'red')
b=sns.lineplot(x =test_df['date'], y = test_df['2.5% Credibilty'], label = 'Credibilty Interval',
color = 'skyblue', alpha=.3)
c=sns.lineplot(x =test_df['date'], y = test_df['97.5% Credibility'], label = 'Credibilty Interval',
color = 'skyblue', alpha=.3)
line = c.get_lines()
plt.fill_between(line[0].get_xdata(), line[1].get_ydata(), line[2].get_ydata(), color='skyblue', alpha=.3)
sns.scatterplot(x =test_df['date'], y = test_df['eaches'], label = 'True Value', color='black')
plt.legend()
I would like to basically add the two x axis as a continuation and maybe add a vertical line to the start of the test period.
CodePudding user response:
Put them on the same axes and use axvline to mark the prediction start. Also, you can fix the overlapping dates on the x-axis by casting the date columns as proper datetimes (train_df["date"] = pd.to_datetime(train_df.date)).
import matplotlib.pyplot as plt
import seaborn as sns
fig, ax = plt.subplots(1, 1, figsize=(15,4))
c_train= sns.scatterplot(x =train_df['date'], y = train_df['eaches'], label = 'Train Eaches',
color = 'black', ax=ax)
a = sns.lineplot(x =test_df['date'], y = test_df['predictions'], label = 'Posterior Prediction', color = 'red', ax=ax)
b = sns.lineplot(x =test_df['date'], y = test_df['2.5% Credibilty'], label = 'Credibilty Interval',
color = 'skyblue', alpha=.3, ax=ax)
c = sns.lineplot(x =test_df['date'], y = test_df['97.5% Credibility'], label = 'Credibilty Interval',
color = 'skyblue', alpha=.3)
line = c.get_lines()
ax.fill_between(line[0].get_xdata(), line[1].get_ydata(), line[2].get_ydata(), color='skyblue', alpha=.3)
sns.scatterplot(x =test_df['date'], y = test_df['eaches'], label = 'True Value', color='black', ax=ax)
ax.legend()
ax.axvline(test_df['date'][0])