I have a dataset containing three columns. I want to compare them together and find out the count as follows using pandas.
Input:
|Key|Name|location|
|---|----|--------|
|112|A | ABCD |
|112|A | ABCD |
|128|B | BCDE |
|138|C | ABCD |
|128|B | BCDE |
|112|A | ABCD |
|115|D | BCDE |
Desired Output:
|location|Name|COUNT |
|--------|----|----------|
|ABCD |A,C |A->1,C-1 |
|BCDE |B,D |B->1 ,D->1|
CodePudding user response:
I agree with @not a robot here. Your desired output is probably not really useful.
Try this:
res = df.drop_duplicates().groupby( 'location')['Name'].agg(Count='value_counts').reset_index()
print(res)
location Name Count
0 ABCD A 1
1 ABCD C 1
2 BCDE B 1
3 BCDE D 1
Or you do it like this to keep all columns ('key'):
df.drop_duplicates().groupby('location').value_counts().reset_index(name='Count')
location Key Name Count
0 ABCD 112 A 1
1 ABCD 138 C 1
2 BCDE 128 B 1
3 BCDE 115 D 1
If your real data is bigger than this, you can set a subset in drop_duplicates to define which rows have to be the same to be considered as duplicates. Without it, all columns must be same to be a duplicate.
CodePudding user response:
Try this code
(
df
# count the number of unique Keys for each location-Name pair
.groupby(['location', 'Name'], as_index=False)['Key'].nunique()
# create a temporary new column the connects Name to its counts
.assign(COUNT=lambda x: x.Name '->' x.Key.astype(str))
# aggregate Name and COUNT by location
.groupby('location', as_index=False)[['Name', 'COUNT']].agg(', '.join)
)
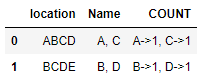
However, it's very difficult to see the above table ever be useful in an EDA context because COUNT is a string column so no further analysis can be done. If you remove everything after the first groupby() in the above code, you can get:
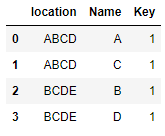
which I believe is much more useful for future analysis.