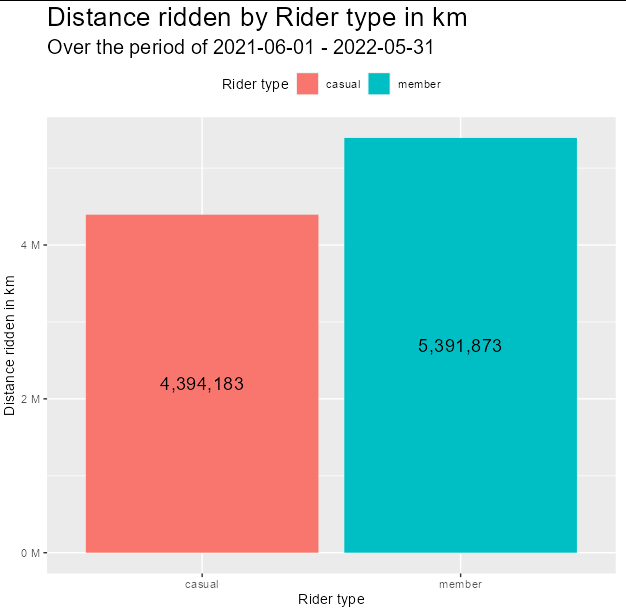
I am trying to label columns with geom_text() on a geom_col() however, the labels (numbers) are not printing out correctly, nor positioning the way I would like them to. vjust does not seem to be working as I wanted the labels to be at the top of the columns (inside them) but they remained at the bottom. The columns should show the total distance ridden by rider type but they are not even readable.
Attached a screenshot on the output of my code below. Hope it's not a duplicate question and really appreciate any help you can give me as I am new to R and I am a little bit stuck with this one.
total_distance_ridden_by_rider_type <-
ggplot(consolidated_data_202106_202205, aes(member_casual, distance))
geom_col(aes(fill = member_casual))
labs(y = "Distance ridden in km",
x = "Rider type",
title = "Distance ridden by Rider type in km",
subtitle = "Over the period of 2021-06-01 - 2022-05-31",
fill = "Rider type")
scale_y_continuous(labels = unit_format(unit = "M", scale = 1e-6))
geom_text(aes(x = member_casual, y = distance, label = comma(distance)),
stat = "identity",
vjust = 1.5,
colour = "black",
size = 5)
theme(legend.position = "top",
plot.title = element_text(size = 20),
plot.subtitle = element_text(size = 15))
Thanks a lot! Janos
CodePudding user response:
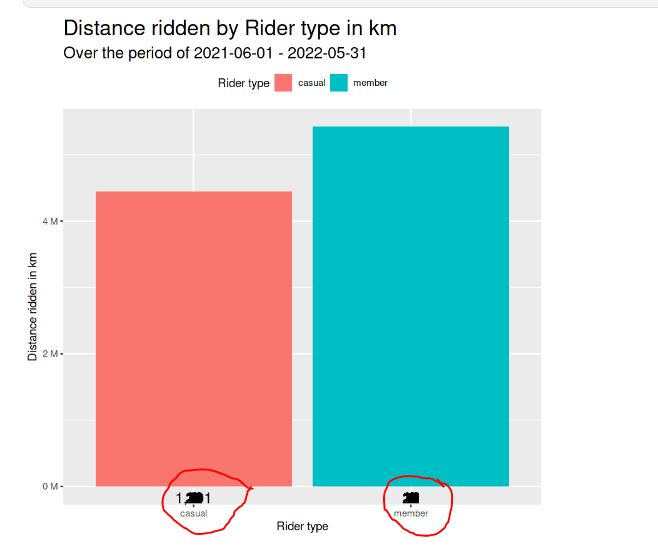
Without your data, it is difficult to be sure, but it seems that your problem is that you are creating your columns by stacking thousands of different distances on top of each other to get the total distance ridden on the y axis. This would be fine, except that you are then trying to plot a label for each individual rider on the chart. Since you are using position = 'identity' for geom text, these will all appear close to the bottom of the plot, since any one rider only rode at most a few thousand Km.
Let us create a little example dataset to ensure we can replicate your problem:
set.seed(1)
consolidated_data_202106_202205 <- data.frame(
member_casual = rep(c('casual', 'member'), each = 1000),
distance = round(rnorm(2000, rep(c(4400, 5400), each = 1000), sd = 500))
)
Now using your exact plotting code, we get a very similar appearance:
library(ggplot2)
library(scales)
ggplot(consolidated_data_202106_202205, aes(member_casual, distance))
geom_col(aes(fill = member_casual))
labs(y = "Distance ridden in km",
x = "Rider type",
title = "Distance ridden by Rider type in km",
subtitle = "Over the period of 2021-06-01 - 2022-05-31",
fill = "Rider type")
scale_y_continuous(labels = unit_format(unit = "M", scale = 1e-6))
geom_text(aes(x = member_casual, y = distance, label = comma(distance)),
stat = "identity",
vjust = 1.5,
colour = "black",
size = 5)
theme(legend.position = "top",
plot.title = element_text(size = 20),
plot.subtitle = element_text(size = 15))
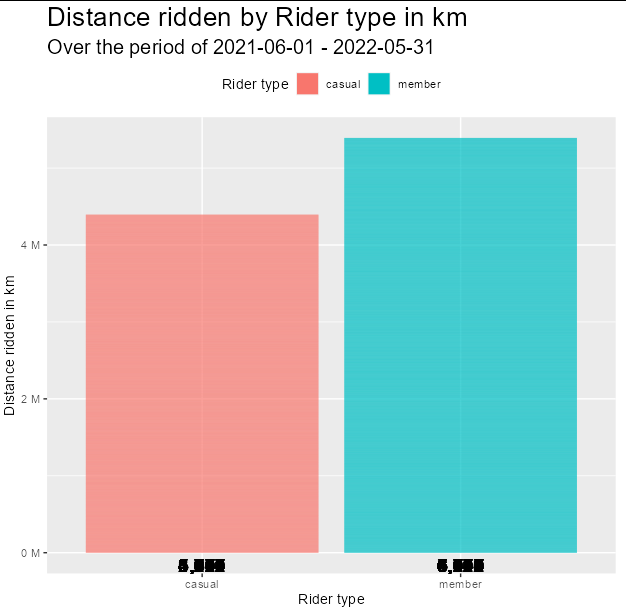
The way to fix this is simply to summarize the data before plotting it. We can use dplyr to help us here:
library(dplyr)
consolidated_data_202106_202205 %>%
group_by(member_casual) %>%
summarize(distance = sum(distance)) %>%
ggplot(aes(member_casual, distance))
geom_col(aes(fill = member_casual))
labs(y = "Distance ridden in km",
x = "Rider type",
title = "Distance ridden by Rider type in km",
subtitle = "Over the period of 2021-06-01 - 2022-05-31",
fill = "Rider type")
scale_y_continuous(labels = unit_format(unit = "M", scale = 1e-6))
geom_text(aes(x = member_casual, y = distance/2, label = comma(distance)),
position = "stack",
colour = "black",
size = 5)
theme(legend.position = "top",
plot.title = element_text(size = 20),
plot.subtitle = element_text(size = 15))