I am trying to transform multiple dictionaries with keys and corresponding lists to a pandas dataframe and can't get to the right way of transforming them. For the pandas data frame, the keys are the index column and the lists
How can I transform python dictionaries with keys and corresponding lists (in values) to a pandas dataframe with keys as the index column and each of the dictionary as the other columns ?
Here is a sample set of dictionaries and one of my non-working solutions:
import pandas as pd
dict1 = {'key_1': [1, 2, 3, 4], 'key_2': [5, 6, 7, 8], 'key_3': [9, 10, 11, 12]}
dict2 = {'key_1': ['a', 'b', 'c', 'd'], 'key_2': ['e', 'f', 'g', 'h'], 'key_3': ['i', 'j', 'k', 'l']}
dict3 = {'key_1': ['DD', 'CC', 'BB', 'AA'], 'key_3': ['II', 'JJ', 'KK', 'LL']}
df = pd.DataFrame.from_dict({'dict1':pd.Series(dict1),
'dict2':pd.Series(dict2),
'dict3':pd.Series(dict3)})
print(df)
This is what I need the resulting dataframe to look like:
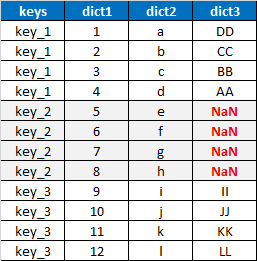
I tried using explode and it would work if I only had one dictionary, but doing it recursively for the other dictionaries did not work. Then, I tried some of the solutions in this Stackoverflow transformation solution but couldn't get the solutions to work, in some cases because of the NaNs in my example.
CodePudding user response:
You would need to fillna with a list with 4 items. Unfortunately fillna doesn't support a list as parameter.
But you can take advantage of a stack/unstack (and the fill_value parameter of unstack), then explode all columns:
(df
.stack()
.unstack(fill_value=[pd.NA]*4)
.explode(list(df))
)
output:
dict1 dict2 dict3
key_1 1 a DD
key_1 2 b CC
key_1 3 c BB
key_1 4 d AA
key_2 5 e <NA>
key_2 6 f <NA>
key_2 7 g <NA>
key_2 8 h <NA>
key_3 9 i II
key_3 10 j JJ
key_3 11 k KK
key_3 12 l LL
CodePudding user response:
Or try:
df_e = df.stack().explode().to_frame()
df_e = df_e.set_index(df_e.groupby(level=[0,1]).cumcount(),
append=True)
df_out = df_e[0].unstack(1)
df_out
Output:
dict1 dict2 dict3
key_1 0 1 a DD
1 2 b CC
2 3 c BB
3 4 d AA
key_2 0 5 e NaN
1 6 f NaN
2 7 g NaN
3 8 h NaN
key_3 0 9 i II
1 10 j JJ
2 11 k KK
3 12 l LL