I am looking for a way to do a modified pandas interpolate so that consecutive NaN values outside the limit aren't filled into the dataframe.
If this is the dataframe that I am starting with:
df = pd.DataFrame({'col1': [0, np.nan, np.nan, np.nan, 3, 4],
'col2': [np.nan, 1, 2, np.nan, 4, np.nan],
'col3': [4, np.nan, np.nan, 7, 10, 11]})
df
col1 col2 col3
0 0.0 NaN 4.0
1 NaN 1.0 NaN
2 NaN 2.0 NaN
3 NaN NaN 7.0
4 3.0 4.0 10.0
5 4.0 NaN 11.0
and I specify that I want to interpolate with a limit of two, with an inside limit area, as seen below:
df.interpolate(method="linear", limit=2, limit_area="inside")
This is the result:
col1 col2 col3
0 0.00 NaN 4.0
1 0.75 1.0 5.0
2 1.50 2.0 6.0
3 NaN 3.0 7.0
4 3.00 4.0 10.0
5 4.00 NaN 11.0
However, I'm looking for an alternate solution so that the interpolate fill only occurs if there equal to or less than the limit NaNs in a row for a specific column. So that, my desired result would look like this:
col1 col2 col3
0 0.00 NaN 4.0
1 NaN 1.0 5.0
2 NaN 2.0 6.0
3 NaN 3.0 7.0
4 3.00 4.0 10.0
5 4.00 NaN 11.0
The first column is not filled because there are more than the limit (2) NaNs in a row.
CodePudding user response:
We can just work on individual columns, and apply:
def interpolate(series, thresh=2):
# where the nan values are
nans = series.isna()
# calculate the size of consecutive `nan`
mask = nans.groupby([(~nans).cumsum(),nans]).transform('size') > thresh
return series.interpolate(method='linear', limit_area='inside').mask(mask)
df.apply(interpolate)
Note: If you do, e.g. interpolate(df['col1']), then mask would be:
0 False
1 True
2 True
3 True
4 False
5 False
Name: col1, dtype: bool
Output:
col1 col2 col3
0 0.0 NaN 4.0
1 NaN 1.0 5.0
2 NaN 2.0 6.0
3 NaN 3.0 7.0
4 3.0 4.0 10.0
5 4.0 NaN 11.0
CodePudding user response:
Find where there is a group of three nan and don't put interpolation values there:
mask = df.rolling(3, 0, center=True).count().eq(0).replace(False, np.nan).bfill(limit=1).ffill(limit=1)
df.where(mask, df.interpolate(limit_area='inside'), inplace=True)
Output:
col1 col2 col3
0 0.0 NaN 4.0
1 NaN 1.0 5.0
2 NaN 2.0 6.0
3 NaN 3.0 7.0
4 3.0 4.0 10.0
5 4.0 NaN 11.0
CodePudding user response:
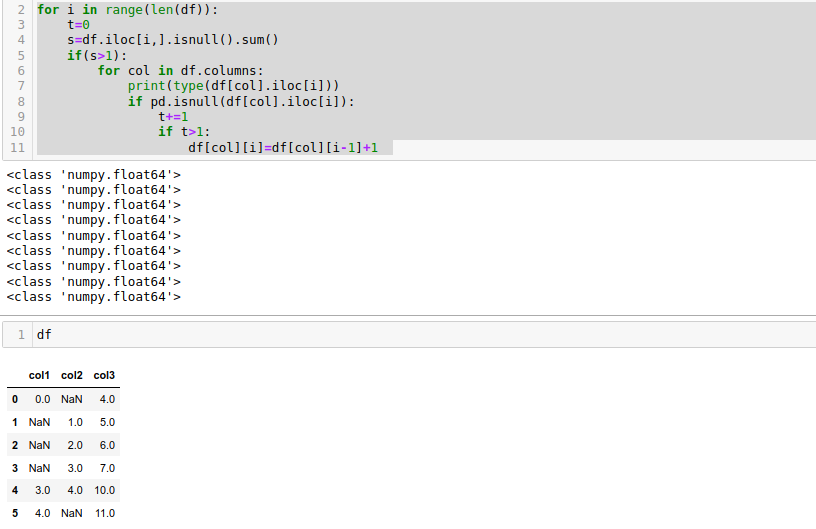
for i in range(len(df)):
t=0
s=df.iloc[i,].isnull().sum()
if(s>1):
for col in df.columns:
print(type(df[col].iloc[i]))
if pd.isnull(df[col].iloc[i]):
t =1
if t>1:
df[col][i]=df[col][i-1] 1