The sample of the dataset I am working on:
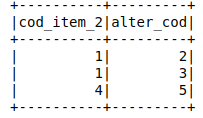
test = sqlContext.createDataFrame([(1,2),
(1,3),
(4,5)],
['cod_item_2','alter_cod'])
test_2 = sqlContext.createDataFrame([(1,"shamp_1"),(2,"shamp_2"),
(4,"tire_1"),(5,"tire_2"),
(3,"shamp_3"),(6,"cookie"),
(7,"flower"),(8,"water")],
['cod_item','product_name'])

The first dataframe contains items and items that are equivalent to them.
The second dataframe contains all items and product names.
I want to use the first dataframe to pull out the items that are equivalent to the second dataframe and replace with the item that represents them (the item on the left side of the first table), where the result is as follows:

I tried doing a full join on both dataframes and using the when clause to change the values. But it ended up not working.
CodePudding user response:
You can do 2 joins. test_2 with test and then again with test_2 (self join). For this to work reliably I use alias on dataframes.
from pyspark.sql import functions as F
test_3 = (
test_2.alias('a')
.join(test, F.col("a.cod_item") == F.col("alter_cod"), "left")
.join(test_2.alias('b'), F.col("cod_item_2") == F.col("b.cod_item"), "left")
.select(
F.coalesce("b.cod_item", "a.cod_item").alias("cod_item"),
F.coalesce("b.product_name", "a.product_name").alias("product_name")
)
)
test_3.show()
# -------- ------------
# |cod_item|product_name|
# -------- ------------
# | 4| tire_1|
# | 1| shamp_1|
# | 1| shamp_1|
# | 4| tire_1|
# | 7| flower|
# | 6| cookie|
# | 1| shamp_1|
# | 8| water|
# -------- ------------