been trying to do an efficient vlookup style on pandas, with IF function...
Basically, I want to apply to this column ccy_grp, that if the value (in a particular row) is 'NaN', it will take the value from another column ccy
def func1(tkn1, tkn2):
if tkn1 == 'NaN:
return tkn2
else:
return tkn1
tmp1_.ccy_grp = tmp1_.apply(lambda x: func1(x.ccy_grp, x.ccy), axis = 1)
but nope, doesn't work. The code cannot seem to detect 'NaN'. I tried another way of np.isnan(tkn1), but I just get a boolean error message...
Any experienced python pandas code developer know?
CodePudding user response:
use pandas.isna to detect a value whether a NaN
- generate data
import pandas as pd
import numpy as np
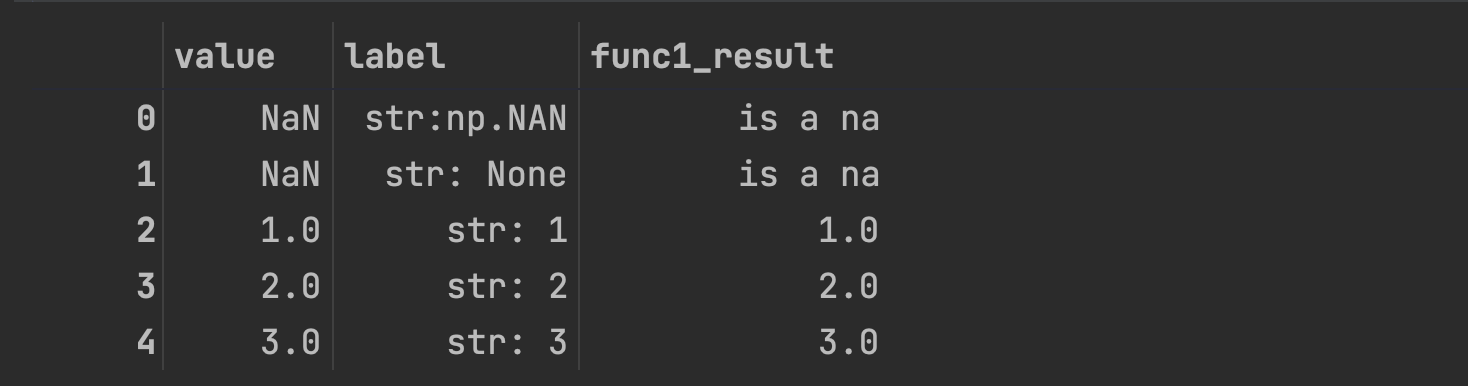
data = pd.DataFrame({'value':[np.NAN, None, 1,2,3],
'label':['str:np.NAN', 'str: None', 'str: 1', 'str: 2', 'str: 3']})
data

- create a function
def func1(x):
if pd.isna(x):
return 'is a na'
else:
return f'{x}'
- apply function to data
data['func1_result'] = data['value'].apply((lambda x: func1(x)))
data
CodePudding user response:
There is a pandas method for what you are trying to do. Check out combine_first:
Update null elements with value in the same location in ‘other’.
Combine two Series objects by filling null values in one Series with non-null values from the other Series.
tmp1_.ccy_grp = tmp1_.ccy_grp.combine_first(tmp1_.ccy)
CodePudding user response:
This looks like it should be a pandas mask/where/fillna problem, not an apply:
Given:
value values2
0 NaN 0.0
1 NaN 0.0
2 1.0 1.0
3 2.0 2.0
4 3.0 3.0
Doing:
df.value.fillna(df.values2, inplace=True)
print(df)
# or
df.value.mask(df.value.isna(), df.values2, inplace=True)
print(df)
# or
df.value.where(df.value.notna(), df.values2, inplace=True)
print(df)
Output:
value values2
0 0.0 0.0
1 0.0 0.0
2 1.0 1.0
3 2.0 2.0
4 3.0 3.0