I'm not quite sure how to ask this question, but I need some clarification on how to make use of Dask's ability to "handle datasets that don't fit into memory", because I'm a little confused on how it works from the CREATION of these datasets.
I have made a reproducible code below that closely emulates my problem. Although this example DOES fit into my 16Gb memory, we can assume that it doesn't because it does take up ALMOST all of my RAM.
I'm working with 1min, 5min, 15min and Daily stock market datasets, all of which have their own technical indicators, so each of these separate dataframes are 234 columns in width, with the 1min dataset having the most rows (521,811), and going down from there. Each of these datasets can be created and fit into memory on their own, but here's where it gets tricky.
I'm trying to merge them column-wise into 1 dataframe, each column prepended with their respective timeframes so I can tell them apart, but this creates the memory problem. This is what I'm looking to accomplish visually:
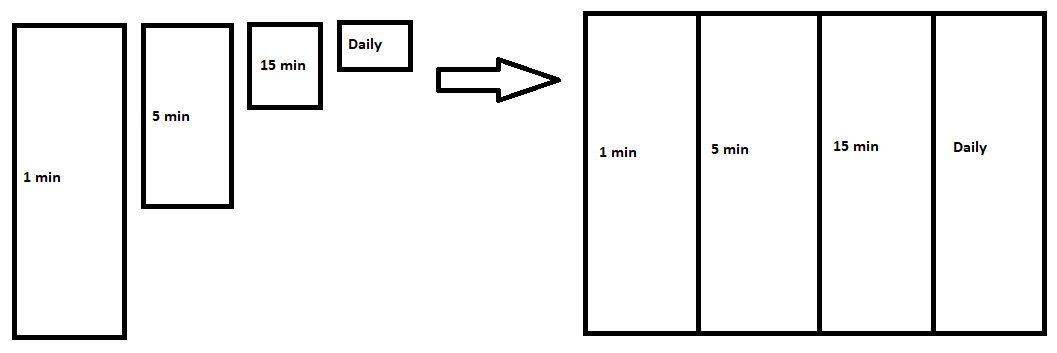
I'm not really sure if Dask is what I need here, but I assume so. I'm NOT looking to use any kind of "parallel calculations" here (yet), I just need a way to create this dataframe before feeding it into a machine learning pipeline (yes, I know it's a stock market problem, just overlook that for now). I know Dask has a machine learning pipeline I can use, so maybe I'll make use of that in the future, however I need a way to save this big dataframe to disk, or create it upon importing it on the fly.
What I need help with is how to do this. Seeing as each of these datasets on their own fit into memory nicely, an idea I had (and this may not be correct at all so please let me know), would be to save each of the dataframes to separate parquet files to disk, then create a Dask dataframe object to import each of them into, when I go to start the machine learning pipeline. Something like this:
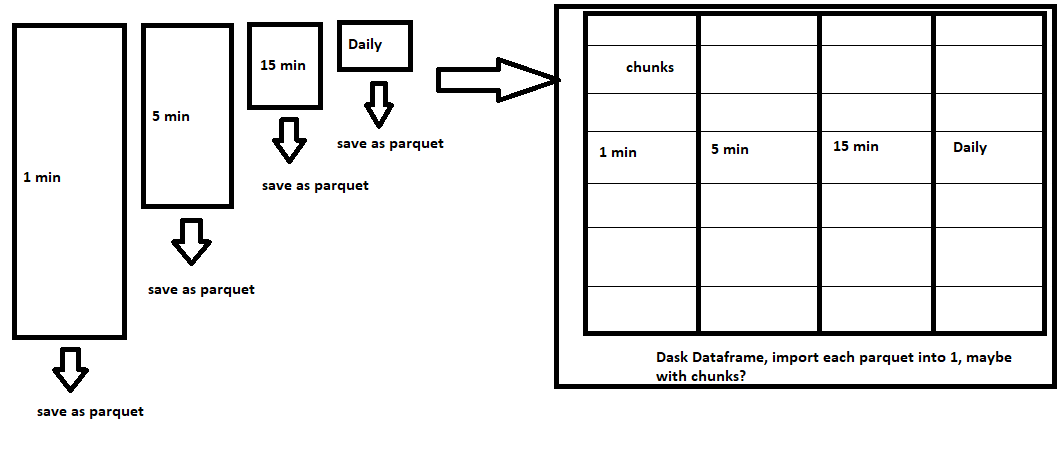
Is this conceptually correct with what I need to do, or am I way off? haha. I've read through the documentation on Dask, and also checked out this guide specifically, which is good, however as a newbie I need some guidance with how to do this for the first time.
How can I create and save this big merged dataframe to disk, if I can't create it in memory in the first place?
Here is my reproducible dataframe/memory problem code. Be careful when you go to run this as it'll eat up your RAM pretty quickly, I have 16Gb of RAM and it does run on my fairly light machine, but not without some red-lining RAM, just wanted to give the Dask gods out there something specific to work with. Thanks!
from pandas import DataFrame, date_range, merge
from numpy import random
# ------------------------------------------------------------------------------------------------ #
# 1 MINUTE DATASET #
# ------------------------------------------------------------------------------------------------ #
ONE_MIN_NUM_OF_ROWS = 521811
ONE_MIN_NUM_OF_COLS = 234
main_df = DataFrame(random.randint(0,100, size=(ONE_MIN_NUM_OF_ROWS, ONE_MIN_NUM_OF_COLS)),
columns=list("col_" str(x) for x in range(ONE_MIN_NUM_OF_COLS)),
index=date_range(start="2019-12-09 04:00:00", freq="min", periods=ONE_MIN_NUM_OF_ROWS))
# ------------------------------------------------------------------------------------------------ #
# 5 MINUTE DATASET #
# ------------------------------------------------------------------------------------------------ #
FIVE_MIN_NUM_OF_ROWS = 117732
FIVE_MIN_NUM_OF_COLS = 234
five_min_df = DataFrame(random.randint(0,100, size=(FIVE_MIN_NUM_OF_ROWS, FIVE_MIN_NUM_OF_COLS)),
columns=list("5_min_col_" str(x) for x in range(FIVE_MIN_NUM_OF_COLS)),
index=date_range(start="2019-12-09 04:00:00", freq="5min", periods=FIVE_MIN_NUM_OF_ROWS))
# Merge the 5 minute to the 1 minute df
main_df = merge(main_df, five_min_df, how="outer", left_index=True, right_index=True, sort=True)
# ------------------------------------------------------------------------------------------------ #
# 15 MINUTE DATASET #
# ------------------------------------------------------------------------------------------------ #
FIFTEEN_MIN_NUM_OF_ROWS = 117732
FIFTEEN_MIN_NUM_OF_COLS = 234
fifteen_min_df = DataFrame(random.randint(0,100, size=(FIFTEEN_MIN_NUM_OF_ROWS, FIFTEEN_MIN_NUM_OF_COLS)),
columns=list("15_min_col_" str(x) for x in range(FIFTEEN_MIN_NUM_OF_COLS)),
index=date_range(start="2019-12-09 04:00:00", freq="15min", periods=FIFTEEN_MIN_NUM_OF_ROWS))
# Merge the 15 minute to the main df
main_df = merge(main_df, fifteen_min_df, how="outer", left_index=True, right_index=True, sort=True)
# ------------------------------------------------------------------------------------------------ #
# DAILY DATASET #
# ------------------------------------------------------------------------------------------------ #
DAILY_NUM_OF_ROWS = 933
DAILY_NUM_OF_COLS = 234
fifteen_min_df = DataFrame(random.randint(0,100, size=(DAILY_NUM_OF_ROWS, DAILY_NUM_OF_COLS)),
columns=list("daily_col_" str(x) for x in range(DAILY_NUM_OF_COLS)),
index=date_range(start="2019-12-09 04:00:00", freq="D", periods=DAILY_NUM_OF_ROWS))
# Merge the daily to the main df (don't worry about "forward peaking" dates)
main_df = merge(main_df, fifteen_min_df, how="outer", left_index=True, right_index=True, sort=True)
# ------------------------------------------------------------------------------------------------ #
# FFILL NAN's #
# ------------------------------------------------------------------------------------------------ #
main_df = main_df.fillna(method="ffill")
# ------------------------------------------------------------------------------------------------ #
# INSPECT #
# ------------------------------------------------------------------------------------------------ #
print(main_df)
CodePudding user response:
I would take the dask.dataframe tutorial and look at the dataframe best practices guide. dask can work with larger-than-memory datasets generally by one of two approaches:
design your job ahead of time, then iterate through partitions of the data, writing the outputs as you go, so that not all of the data is in memory at the same time.
use a distributed cluster to leverage more (distributed) memory than exists on any one machine.
It sounds like you're looking for approach (1). The actual implementation will depend on how you access/generate the data, but generally I'd say you should not think of the job as "generate the larger-than-memory dataset in memory then dump it into the dask dataframe". Instead, you'll need to think carefully about how to load the data partition-by-partition, so that each partition can work independently.
Modifying your example, the full workflow might look something like this:
import pandas as pd, numpy as np, dask.dataframe, dask.delayed
@dask.delayed
def load_data_subset(start_date, freq, periods):
# presumably, you'd query some API or something here
dummy_ind = pd.date_range(start_date, freq=freq, periods=periods)
dummy_response = pd.DataFrame(
np.random.randint(0, 100, size=(len(dummy_ind), 234)),
columns=list("daily_col_" str(x) for x in range(234)),
index=dummy_ind
)
return dummy_response
# generate a partitioned dataset with a configurable frequency, with each dataframe having a consistent number of rows.
FIFTEEN_MIN_NUM_OF_ROWS = 117732
full_index = pd.date_range(
start="2019-12-09 04:00:00",
freq="15min",
periods=FIFTEEN_MIN_NUM_OF_ROWS,
)
df_15min = dask.dataframe.from_delayed([
load_data_subset(full_index[i], freq="15min", periods=10000)
for i in range(0, FIFTEEN_MIN_NUM_OF_ROWS, 10000)
])
You could now write these to disk, concat, etc, and at any given point, each dask worker will only be working with 10,000 rows at a time. Ideally, you'll design the chunks so each partition will have a couple hundred MBs each - see the best practices section on partition sizing.