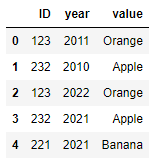
Lets say I have a dataframe:
df =
|ID | year | value |
|----|------|----------|
|123 | 2011 | Mango |
|232 | 2010 | Pineapple|
|123 | 2022 | Orange |
|232 | 2021 | Apple |
|221 | 2021 | Banana |
I want to update the dataframe value with the latest years value. I am expecting a final df as:
|ID | year | value |
|----|------|----------|
|123 | 2011 | Orange |
|232 | 2010 | Apple |
|123 | 2022 | Orange |
|232 | 2021 | Apple |
|221 | 2021 | Banana |
Basically we want to update the values with the latest year's values. So in this case, id - 123 is appearing twice in the same df. They both have different values "Mango" in 2011 and "Orange" in 2022. We wish to have a new df created with same columns and same repetitions but with latest year's values.
I need this to be done without using any loops as the originial df is extremely huge and using any loop is taking huge time to run
CodePudding user response:
You need to use 'Rank' & 'Merge' as below, gives required output
df = pd.DataFrame({'ID':[123,232,123,232,221],'Year':[2011,2010,2022,2021,2021],'Value':['Mango','Pineapple','Orange','Apple','Banana']})
df['ID_Year_Rank'] = df.groupby(['ID'])['Year'].rank(method='first', ascending=False)
df
This will add a rank == 1 to each row where year is latest in every ID
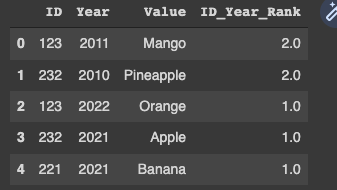
After this simple merge with itself based on filtered values give required result
pd.merge(df[['ID','Year']], df[df['ID_Year_Rank']==1][['ID','Value']], left_on='ID', right_on = 'ID')
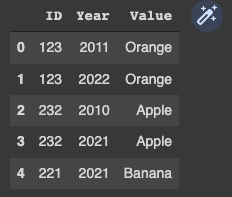
CodePudding user response:
Try this. Use the indices of each ID's most recent year to index value column with it using loc[] accessor.
# indices of last years of each ID
indx = df.groupby('ID')['year'].transform('idxmax')
# assign values corresponding to the last years back to value
df['value'] = df.loc[indx, 'value'].tolist()
df