My test set data contains about 50,000 instances. I trained different machine learning models. Now I want to do some comparison to see for example if for every instance x_i that model A predicted as 0, models B and C also predicted that instance as 0.
For example, below are the first 5 predictions by the models.
import pandas as pd
data = {'true_class': [3.0, 3.0, 3.0, 3.0, 3.0],
'rf_pred': [3.0, 0.0, 0.0, 0.0, 0.0],
'mlp_pred': [3.0, 0.0, 0.0, 0.0, 0.0],
'knn_pred': [3.0, 0.0, 0.0, 0.0, 0.0],
'lg_pred': [3.0, 0.0, 0.0, 0.0, 0.0],
'ada_pred': [2.0, 2.0, 2.0, 2.0, 2.0]}
df = pd.DataFrame(data)
df
true_class rf_pred mlp_pred knn_pred lg_pred ada_pred
0 3.0 3.0 3.0 3.0 3.0 2.0
1 3.0 0.0 0.0 0.0 0.0 2.0
2 3.0 0.0 0.0 0.0 0.0 2.0
3 3.0 0.0 0.0 0.0 0.0 2.0
4 3.0 0.0 0.0 0.0 0.0 2.0
Clearly predictions of rf_pred, mlp_pred, knn_pred & lg_pred are the same for these five instances.
Is there any way to perform such analysis, per haps visually?
CodePudding user response:
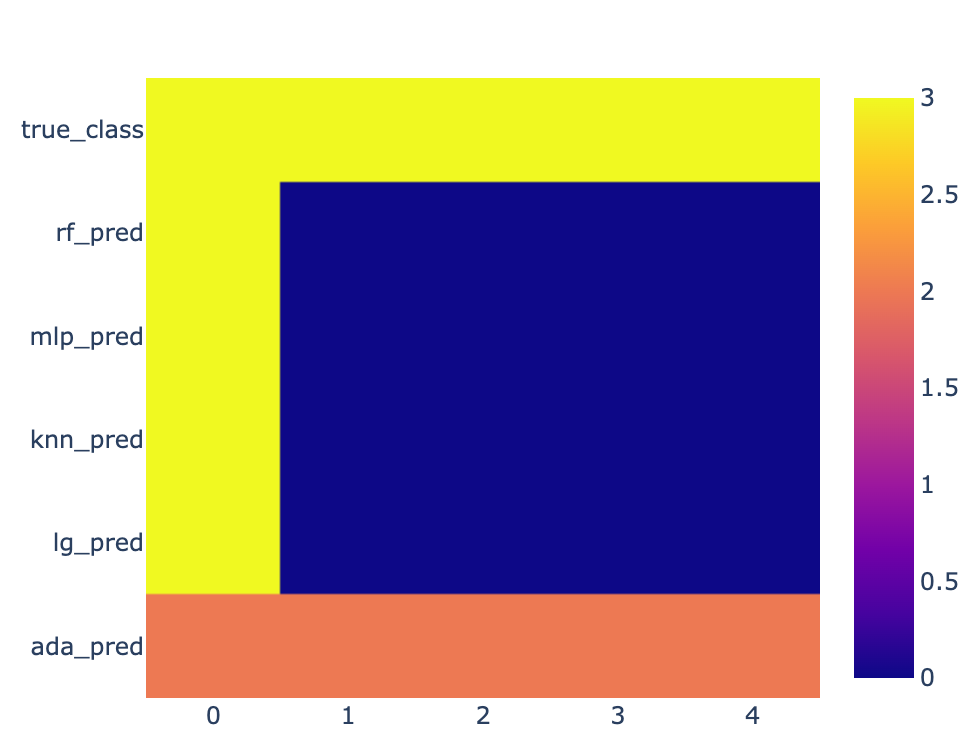
Here's a heatmap approach: Each row shows a model's predictions, each column is an instance predicted and the color represents the value predicted.
import plotly.express as px
fig = px.imshow(list(data.values()), y = list(data.keys()))
fig.show()
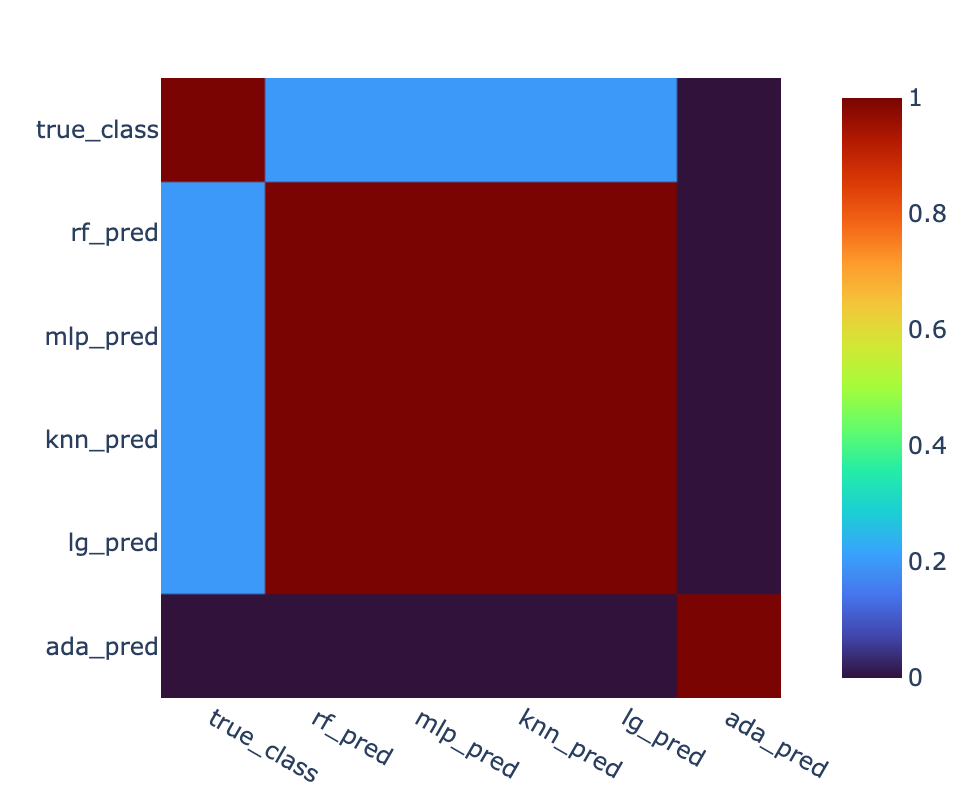
Secondly you could compare models with each other, by comparing the rates at which they predict the same category for the same instance.
import pandas as pd
df = pd.DataFrame(data)
rate_of_same_prediction = df.apply(lambda x:[ (x== df[ col ]).mean() for col in df.columns], axis=0)
rate_of_same_prediction.index = rate_of_same_prediction.columns
fig = px.imshow(rate_of_same_prediction)
fig.show()
Here both columns and rows represent your models.
CodePudding user response:
import matplotlib.pyplot as plt
To check the relationship between those predictions
plt.scatter(df[true_class], df[rf_pred])
You can as well use the (df.corr()) method or use the regplot method in seaborn