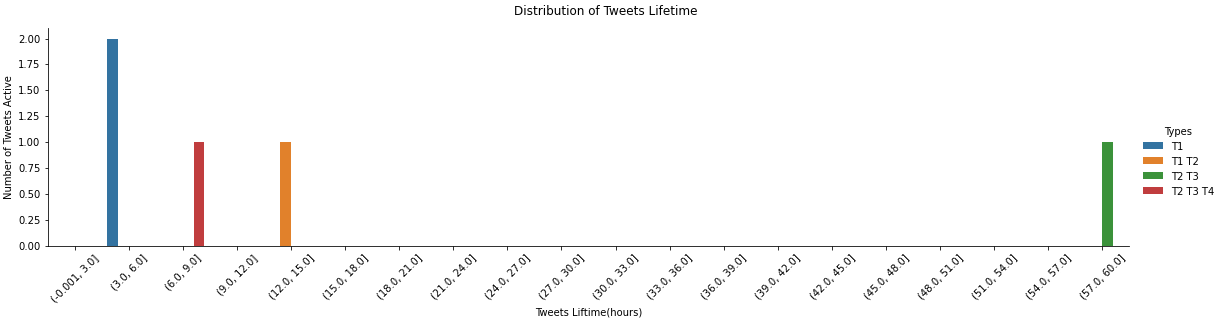
I have a Pandas df of ~1000 tweet ids and their lifetime in seconds (lifetime is the time distance between the first and last retweet). Below is the head of a subset of my df:
| tweet_id | lifetime(timedelta) | lifetime(hours) | type1 | type2 | type3 | type4 |
|---|---|---|---|---|---|---|
| 329664 | 0 days 05:27:22 | 5.456111 | 1 | 0 | 0 | 0 |
| 722624 | 0 days 12:43:43 | 12.728611 | 1 | 1 | 0 | 0 |
| 866498 | 2 days 09:00:28 | 57.007778 | 0 | 1 | 1 | 0 |
| 156801 | 0 days 03:01:29 | 3.024722 | 1 | 0 | 0 | 0 |
| 941440 | 0 days 06:39:58 | 6.666111 | 0 | 1 | 1 | 1 |
Note1: tweets' lifetime is shown in two columns (columns have different dtypes):
- column
lifetime(timedelta)shows tweets lifetime in timedelta64[ns] format, - column
lifetime(hours)shows tweets lifetime in hours (float64 type). I created column 2 by extracting hours from lifetime(timedelta) column using:df['lifetime_hours'] = df['lifetime(timedelta)'] / np.timedelta64(1, 'h')
Note2: A tweet can belong to more than one type. For example, tweet id:329664 is only type1, while tweet id: 722624 is type1 and type2.
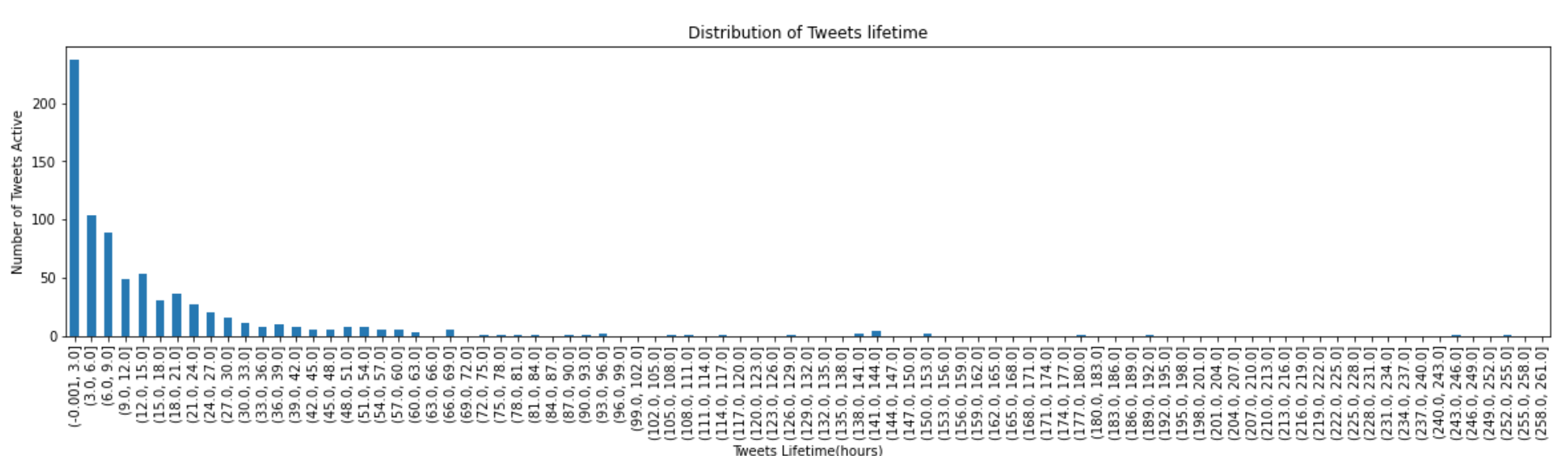
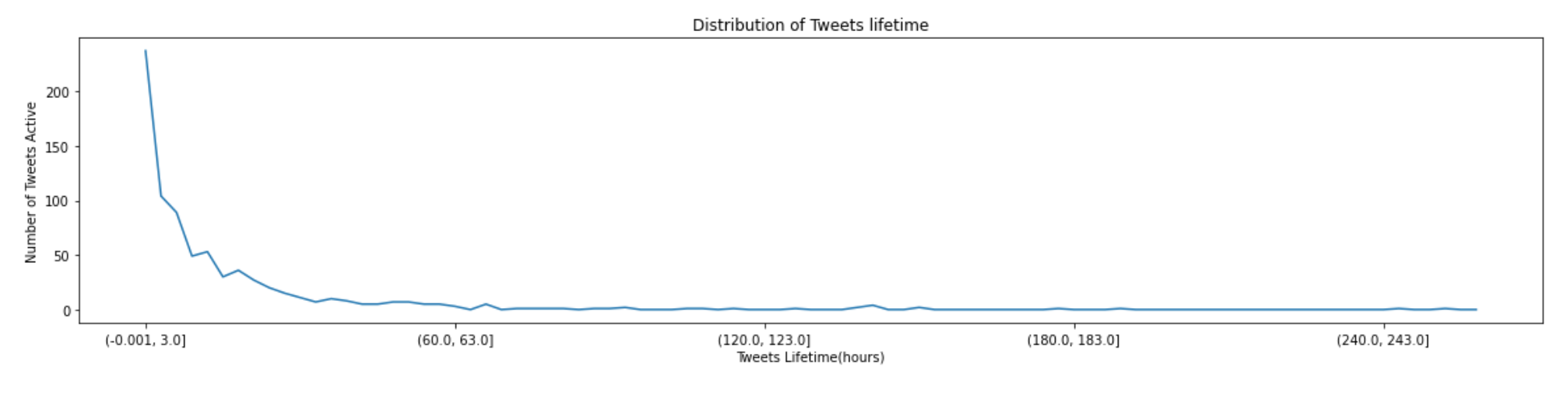
I'd like to plot the distribution of tweets' lifetime for different types of tweets. I could plot the distribution of tweets' lifetime as follows (for all tweets):
Here is the bar chart:
and here is the plot:
Here is how I created the above plots (e.g., the bar plot):
bins = range(0, df['lifetime_hours'].max().astype(int), 3)
data = pd.cut(df['lifetime_hours'], bins, include_lowest=True)
from matplotlib.pyplot import figure
plt.figure(figsize=(20,4))
data.value_counts().sort_index().plot(kind='bar')
plt.xlabel('Tweets Lifetime(hours)')
plt.ylabel('Number of Tweets Active')
plt.title('Distribution of Tweets lifetime')
My question is: How to draw the tweets' lifetime distribution for both types in one plot?
Can someone please help me with this?
CodePudding user response:
- In order to separate the data by types, there should be a single identifier column.
- This can be created by multiplying the
0and1column values by the column type names, and then joining the column values into a single string as a new column.
- This can be created by multiplying the
- Tested in
python 3.10,pandas 1.4.2,matplotlib 3.5.1,seaborn 0.11.2
Imports and DataFrame
import pandas as pd
import numpy as np
import seaborn as sns
# start data
data = {'tweet_id': [329664, 722624, 866498, 156801, 941440],
'lifetime(timedelta)': [pd.Timedelta('0 days 05:27:22'), pd.Timedelta('0 days 12:43:43'), pd.Timedelta('2 days 09:00:28'),
pd.Timedelta('0 days 03:01:29'), pd.Timedelta('0 days 06:39:58')],
'type1': [1, 1, 0, 1, 0], 'type2': [0, 1, 1, 0, 1], 'type3': [0, 0, 1, 0, 1], 'type4': [0, 0, 0, 0, 1]}
df = pd.DataFrame(data)
# insert hours columns
df.insert(loc=2, column='lifetime(hours)', value=df['lifetime(timedelta)'].div(pd.Timedelta('1 hour')))
# there can be 15 combinations of types for the 4 type columns
# it's best to rename the columns for ease of use
# rename the type columns; can also use df.rename(...)
cols = ['T1', 'T2', 'T3', 'T4']
df.columns = df.columns[:3].tolist() cols
# create a new column as a unique identifier for types
types = df[cols].mul(cols).replace('', np.nan).dropna(how='all')
df['Types'] = types.apply(lambda row: ' '.join(row.dropna()), axis=1)
# create a column for the bins
bins = range(0, df['lifetime(hours)'].astype(int).add(4).max(), 3)
df['Tweets Liftime(hours)'] = pd.cut(df['lifetime(hours)'], bins, include_lowest=True)
# display(df)
tweet_id lifetime(timedelta) lifetime(hours) T1 T2 T3 T4 Types Tweets Liftime(hours)
0 329664 0 days 05:27:22 5.456111 1 0 0 0 T1 (3.0, 6.0]
1 722624 0 days 12:43:43 12.728611 1 1 0 0 T1 T2 (12.0, 15.0]
2 866498 2 days 09:00:28 57.007778 0 1 1 0 T2 T3 (57.0, 60.0]
3 156801 0 days 03:01:29 3.024722 1 0 0 0 T1 (3.0, 6.0]
4 941440 0 days 06:39:58 6.666111 0 1 1 1 T2 T3 T4 (6.0, 9.0]
Create a Frequency Table
ct = pd.crosstab(df['Tweets Liftime(hours)'], df['Types'])
# display(ct)
Types T1 T1 T2 T2 T3 T2 T3 T4
Tweets Liftime(hours)
(3.0, 6.0] 2 0 0 0
(6.0, 9.0] 0 0 0 1
(12.0, 15.0] 0 1 0 0
(57.0, 60.0] 0 0 1 0
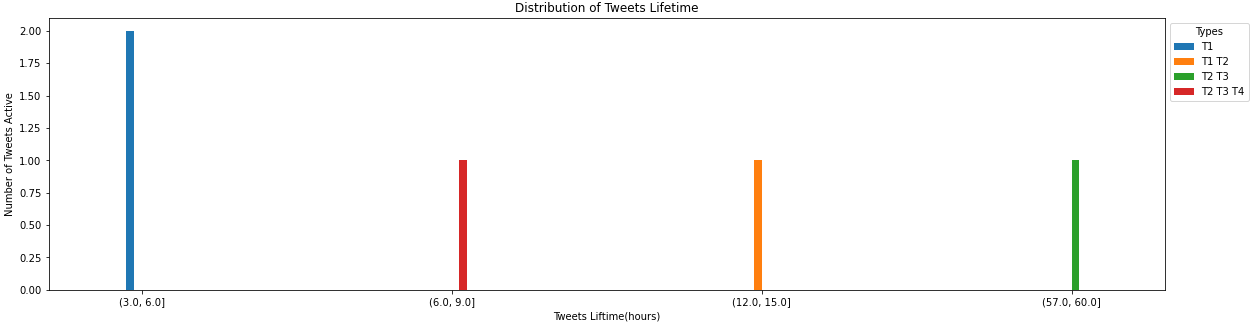
Plot
pandas.DataFrame.plot
- Uses
ct
ax = ct.plot(kind='bar', figsize=(20, 5), width=0.1, rot=0)
ax.set(ylabel='Number of Tweets Active', title='Distribution of Tweets Lifetime')
ax.legend(title='Types', bbox_to_anchor=(1, 1), loc='upper left')
seaborn.catplot
- Uses
dfwithout the need to reshape
p = sns.catplot(kind='count', data=df, x='Tweets Liftime(hours)', height=4, aspect=4, hue='Types')
p.set_xticklabels(rotation=45)
p.fig.subplots_adjust(top=0.9)
p.fig.suptitle('Distribution of Tweets Lifetime')
p.axes[0, 0].set_ylabel('Number of Tweets Active')