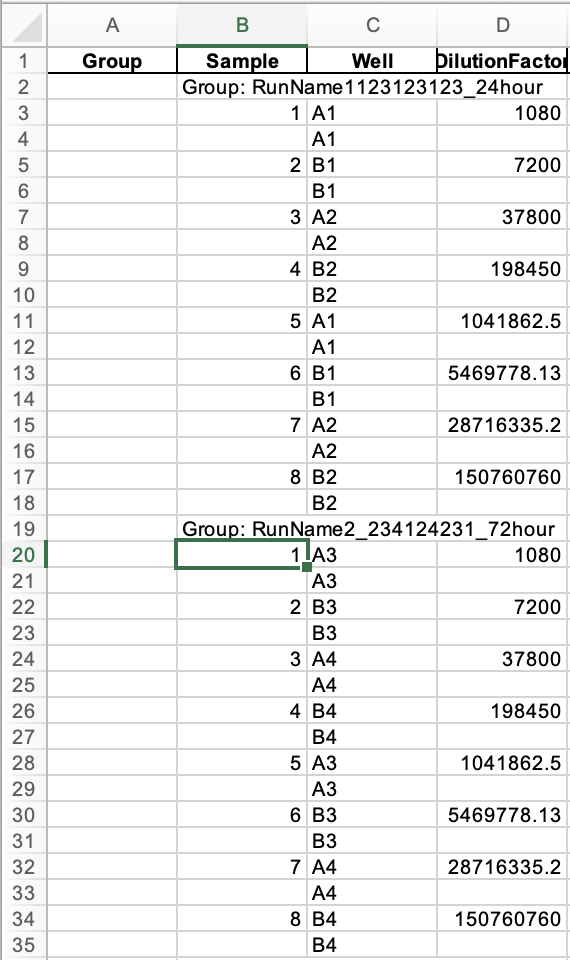
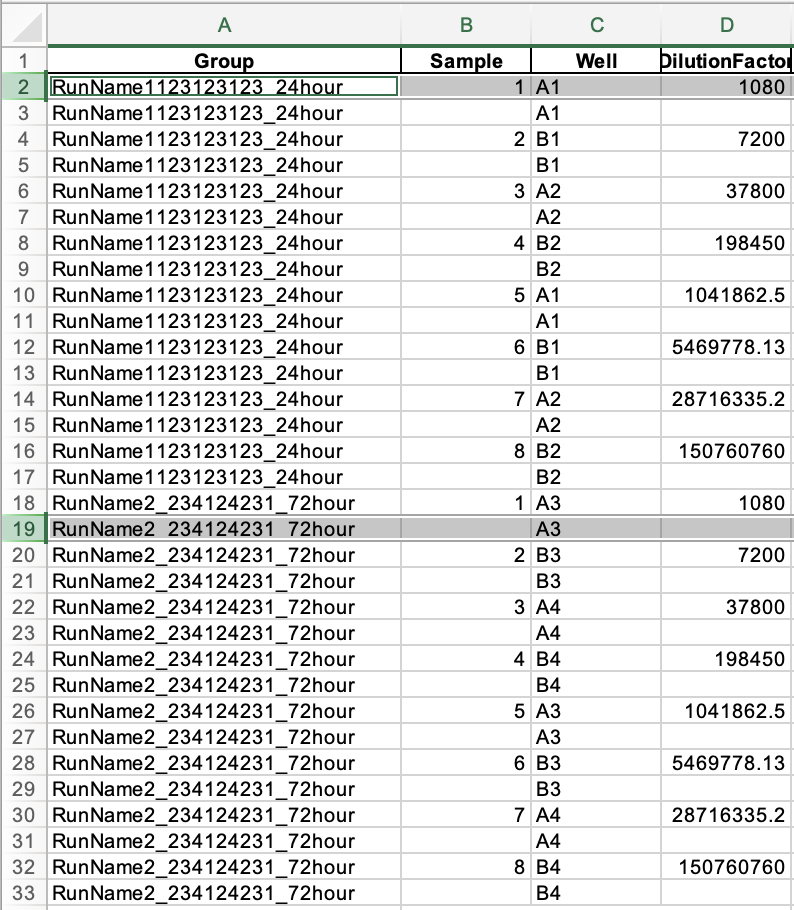
I have a dataframe and there is a specific string I want to pull out and delete apart of it. The string repeats throughout the file with different endings. I want to find part of the string, delete some of it, and add the part I want to keep to several columns. I have an empty dataframe column that I want to add the kept part too. I have included a picture of the current dataframe with the empty column where I want the data to go. I will also add a screenshot of what I want the data to look like. I want it too repeat this until there is no longer that specific string.
CodePudding user response:
As long as you have a way of identifying the values you want to turn into the group data and a way of manipulating those values to make them what you want, then you can do something like this.
import pandas as pd
data = [
[None, 'Group: X', None, None],
[None, 1, 'A1', 20],
[None, 1, 'A1', None],
[None, 2, 'B1', 40],
[None, 2, 'B1', None],
[None, 'Group: Y', None, None],
[None, 1, 'A1', 30],
[None, 1, 'A1', None],
[None, 2, 'B1', 60],
[None, 2, 'B1', None],
]
columns = ['Group', 'Sample', 'Well', 'DiluationFactor']
def identifying_function(value):
return isinstance(value, str) and 'Group: ' in value
def manipulating_function(value):
return value.replace('Group: ', '')
df = pd.DataFrame(data=data, columns=columns)
print(df)
# identify which rows contain the group data
mask = df['Sample'].apply(identifying_function)
# manipulate the data from those rows and write them to the Group column
df.loc[mask, 'Group'] = df.loc[mask, 'Sample'].apply(manipulating_function)
# forward fill the Group column
df['Group'].ffill(inplace=True)
# eliminate the no longer needed rows
df = df.loc[~mask]
print(df)
DataFrame Before:
Group Sample Well DiluationFactor
0 None Group: X None NaN
1 None 1 A1 20.0
2 None 1 A1 NaN
3 None 2 B1 40.0
4 None 2 B1 NaN
5 None Group: Y None NaN
6 None 1 A1 30.0
7 None 1 A1 NaN
8 None 2 B1 60.0
9 None 2 B1 NaN
DataFrame After:
Group Sample Well DiluationFactor
1 X 1 A1 20.0
2 X 1 A1 NaN
3 X 2 B1 40.0
4 X 2 B1 NaN
6 Y 1 A1 30.0
7 Y 1 A1 NaN
8 Y 2 B1 60.0
9 Y 2 B1 NaN