I have a .tsv file displayed below and I want to make dataframe of it using pandas. I am getting error tokenizing data. How can I overcome this error ?
Tsv file (data):
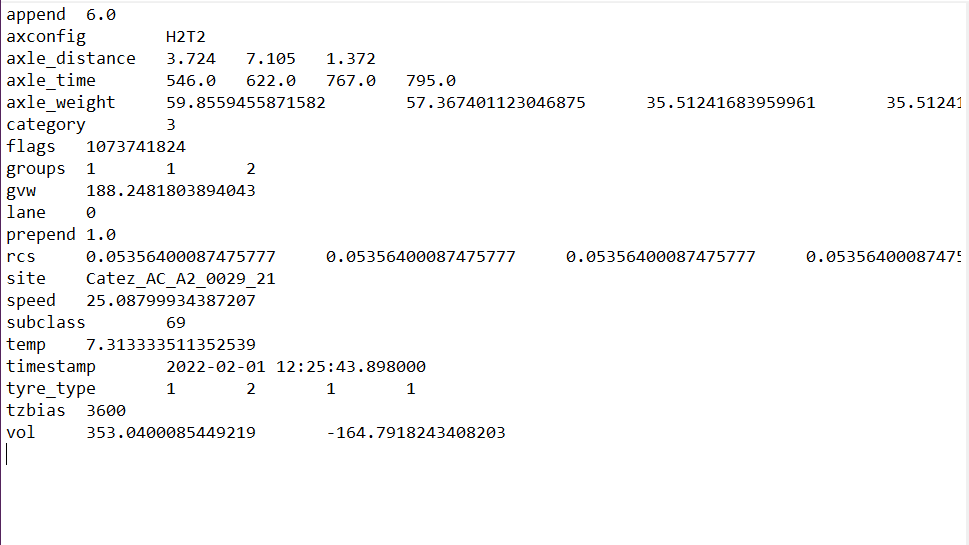
Input:
import pandas as pd
df = pd.read_csv("something/something.tsv", sep='\t')
Output:
ParserError: Error tokenizing data. C error: Expected 2 fields in line 3, saw 4
CodePudding user response:
read_csv is by default taking your first line as a header. append and 6.0 become your two headers. Then it looks for two columns in subsequent rows. In line 3 it finds 4 values and vomits.
You need another approach to handle this data where each line is a key-value pair with multiple values present.
Per your comment - just read it all anyway
Here's how you can do that:
import pandas as pd
import numpy as np
df = pd.read_csv("something/something.tsv", sep='\t', header=None, names=np.arange(20))
names=np.arange(20) is the key - and can be whatever number is more than the number of values you will have in a row. Then you can do whatever you need to do to get the data the way you want it.